1. Introduction
 Imagine you’re watching your favorite show on Netflix. As the next episode auto-plays, you might not realize that behind the scenes, there’s a complex backend system working tirelessly to serve you a seamless experience. Now, take a moment to think about what makes these systems not only functional but also smart. That’s where machine learning (ML) enters the picture—a transformative technology that breathes life into backend development, turning it into something dynamic and innovative.
Imagine you’re watching your favorite show on Netflix. As the next episode auto-plays, you might not realize that behind the scenes, there’s a complex backend system working tirelessly to serve you a seamless experience. Now, take a moment to think about what makes these systems not only functional but also smart. That’s where machine learning (ML) enters the picture—a transformative technology that breathes life into backend development, turning it into something dynamic and innovative.
Backend systems are like the unsung heroes of technology. They don’t get the spotlight but handle the heavy lifting. Whether it’s a payment gateway processing millions of transactions per second or a social media platform keeping billions connected, backends form the backbone of our digital world. But here’s the thing: traditional backends can only do so much. With increasing complexity and the need for smarter solutions, ML has become a necessity.
So, why should you care about ML in backend development? Great question. Let’s explore how this game-changing technology is reshaping the way backends are designed, deployed, and maintained.
a. A World Without Machine Learning
Imagine driving a car with no GPS, cruise control, or smart features. Sure, you’ll get to your destination, but the journey will be riddled with inefficiencies. That’s what backend systems were like before ML—a lot of manual effort, trial-and-error optimizations, and reactive problem-solving.
Now, imagine a car that adapts to traffic conditions, predicts fuel needs, and even suggests alternate routes. That’s the leap ML provides to backends. It automates, predicts, and personalizes, making systems not just functional but intuitive.
Fun Fact: Did you know that Amazon’s recommendation engine contributes to 35% of its revenue? This wouldn’t be possible without ML-powered backends analyzing user data in real time.
b. Why Machine Learning is a Big Deal
- Anticipating Needs:
Ever wondered how Google Maps predicts traffic or Spotify curates playlists? These aren’t lucky guesses. ML models analyze patterns and behaviors, anticipating what users will need next.
- Handling Complexity:
Modern systems handle billions of requests per day. Managing this scale manually is a nightmare. ML automates resource allocation, error detection, and even user authentication, making these systems smarter and faster.
- Personalization at Scale:
Today’s users demand personalized experiences. Whether it’s Netflix suggesting what to watch next or e-commerce platforms showcasing items you’re likely to buy, ML ensures these experiences are tailored, even for millions of users simultaneously.
c. From Reactive to Proactive Systems
Traditional backends are reactive. They wait for something to break, then fix it. Machine learning flips this script. It enables proactive systems that predict issues before they occur. For instance:
- An e-commerce platform can predict server load spikes during sales events and allocate resources in advance.
- A banking system can identify unusual transactions and flag potential fraud instantly.
This proactive approach not only saves time and money but also enhances user trust and satisfaction.
Pro Tip: Incorporating even a basic anomaly detection algorithm can significantly improve backend reliability.
d. Real-World Transformations
ML isn’t just a theoretical concept; it’s revolutionizing industries:
- Healthcare: Backend ML systems analyze patient records to predict disease risks and recommend treatments.
- Retail: Dynamic pricing and stock optimization are driven by backend ML algorithms.
- Entertainment: Platforms like YouTube use backend ML to analyze watch times, generating personalized recommendations.
e. A Glimpse into the Future
The integration of ML into backend systems is only the beginning. With advancements in quantum computing, federated learning, and artificial intelligence ethics, we’re looking at a future where backends not only respond to user needs but also align with global trends and values.
Thought-Provoking Idea: What if your smart home’s backend could anticipate your mood based on your activity patterns and adjust lighting or music accordingly? This isn’t far-fetched; it’s the next step in backend innovation.
f. Why This Blog is Your Guide
By the time you finish this blog, you’ll have a solid understanding of 15 innovative ML techniques that are reshaping backend development. But it’s not just about knowing the concepts—it’s about understanding how to apply them effectively, even if you’re not a data scientist.
And here’s the kicker: You don’t need a PhD to grasp these ideas. We’ll explain everything in a conversational tone, sprinkled with humor and relatable examples. Because learning should be fun, right?
g. Call to Adventure
Ready to dive into the fascinating world of ML-powered backend systems? Let’s get started with an engaging exploration of these techniques, how they’re applied, and why they’re changing the game. Trust me, by the end, you’ll be looking at backend development in an entirely new light.
Fun Fact to Wrap Up: Did you know the term “machine learning” was coined in 1959 by Arthur Samuel, a computer scientist who taught a computer to play checkers? It was groundbreaking then, and it’s reshaping the world now.
2. The Importance of Machine Learning in Backend Development
 If we were to think of backend systems as the invisible gears of the digital world, then machine learning (ML) would be the oil that keeps those gears running smoothly. It’s not just a cool buzzword you hear about in tech conferences; ML has become an integral part of modern backend development, helping businesses stay ahead of the curve, optimize their processes, and deliver an enhanced user experience. So, why is ML so important in backend development? Let’s dive in and explore how it’s changing the game.
If we were to think of backend systems as the invisible gears of the digital world, then machine learning (ML) would be the oil that keeps those gears running smoothly. It’s not just a cool buzzword you hear about in tech conferences; ML has become an integral part of modern backend development, helping businesses stay ahead of the curve, optimize their processes, and deliver an enhanced user experience. So, why is ML so important in backend development? Let’s dive in and explore how it’s changing the game.
a. From Basic to Brainy: The Evolution of Backend Systems
In the early days of backend development, systems were fairly simple. Databases stored information, servers delivered requests, and business logic was straightforward. However, as the digital world grew, so did the need for smarter, more efficient systems. Manual optimization couldn’t keep up with the ever-increasing data flow, security concerns, and the demand for personalized experiences. That’s when ML stepped in.
Before ML, backend systems were reactive. They only responded to problems after they arose—like a firefighter putting out a fire. But ML is proactive. It doesn’t wait for problems to show up. Instead, it uses data to predict what will happen next and takes preventive action. This shift from reactive to proactive is why ML is such a powerful tool in backend development.
Fun Fact: Did you know that Google’s backend uses machine learning to predict search queries? It doesn’t just look at what you’ve searched for; it anticipates what you might search based on trends, location, and even the weather!
b. How ML Makes Backend Systems Smarter
- Predicting Resource Needs:
Think of ML as a backstage manager who knows exactly how many actors, props, and lights are needed for a show before the curtain even goes up. In backend development, this means predicting traffic spikes, resource shortages, and even potential server failures. With ML, your system doesn’t just react to requests but anticipates them. For example, if your website experiences more traffic during certain times of the year, ML models can forecast this and scale resources accordingly. No more crashing websites or slow loading times!
- Automating Routine Tasks:
We all know how repetitive tasks can drain productivity, and in backend development, there’s no shortage of them. But ML can automate many of these processes. Whether it’s data cleansing, sorting through logs to find anomalies, or managing user sessions, ML can handle these tasks faster and more efficiently than any human ever could. Think of it as your trusty assistant who’s always on the ball, never needing a break.
- Improving Data Management:
Backend systems are constantly dealing with vast amounts of data. ML helps make sense of this data by automating data classification, error detection, and even recommending optimizations. If your system receives millions of requests per minute, how do you know which ones are valid and which ones are potentially harmful? ML can flag unusual patterns and prevent security threats, allowing backend developers to focus on what truly matters.
- Personalization at Scale:
One of the most powerful aspects of ML is its ability to deliver personalized experiences. Whether it’s recommending the next movie on Netflix, products on Amazon, or songs on Spotify, ML takes into account a user’s history, preferences, and behavior to provide recommendations. In backend development, this means ML can tailor the user experience for each individual without the need for constant manual adjustments. It’s like having a personal assistant for each user, always making sure they get the most relevant content.
c. Enhancing Security and User Experience
In a world where cybersecurity threats are on the rise, backend systems need to be as secure as possible. Here’s where ML really shows its muscle. Instead of relying on static firewalls and predefined rules, ML can help systems learn to detect new types of attacks in real-time.
For instance, ML models can analyze login attempts, detect patterns, and flag suspicious activity before it becomes a serious issue. Imagine your backend system noticing an unusual login attempt from an unfamiliar location at 3 a.m. ML algorithms can immediately trigger security measures—like multi-factor authentication or account suspension—without waiting for a human to intervene. This not only keeps data safe but also provides users with peace of mind.
Additionally, ML helps enhance the overall user experience by anticipating what users want and need. Instead of bombarding them with irrelevant information, ML can ensure that users see what they care about most, based on past interactions. This results in a more seamless, engaging experience, leading to higher user satisfaction and retention.
d. Scalability and Flexibility: The Backbone of Growing Systems
As businesses grow, so do their backend systems. What worked for 100 users won’t necessarily work for 1 million. Scaling backend infrastructure used to be a nightmare, requiring manual intervention and constant adjustments. But ML changes all of that by automating scaling decisions.
Imagine an e-commerce platform running a flash sale. Without ML, you’d have to anticipate how many servers to bring online, manually configure them, and hope for the best. With ML, the system can learn from previous sales, predict the traffic load, and automatically adjust resources in real-time, ensuring the site runs smoothly regardless of demand. This not only saves time but ensures your users don’t experience frustrating delays or downtime.
e. Real-Time Data Processing: The Competitive Edge
In today’s fast-paced world, data doesn’t wait. It’s generated every second, and businesses need to process it quickly to make informed decisions. This is where ML comes in. By analyzing data in real-time, ML models can provide instant insights, detect anomalies, and trigger actions based on live data.
For example, imagine a backend system for a stock trading platform. Real-time data is crucial, and ML can analyze price fluctuations, news events, and even social media sentiment to predict market movements. This gives traders a competitive edge, helping them make decisions faster than ever before.
f. Wrapping It Up: Why ML is Here to Stay
Machine learning has quickly moved from a niche technology to a cornerstone of modern backend development. It enables systems to predict, learn, and adapt, making them faster, smarter, and more reliable. From automating routine tasks to improving security, personalization, and scalability, ML is helping backend developers create systems that not only meet user expectations but exceed them.
Whether you’re developing a mobile app, an e-commerce platform, or a social network, ML can enhance your backend in ways you may never have imagined. And as this technology continues to evolve, the possibilities are endless. One thing is certain—machine learning is here to stay, and its impact on backend development will only grow in the coming years.
Pro Tip: Start small with ML integration. Even a simple anomaly detection system can improve backend performance and security significantly.
3. 15 Innovative Machine Learning Techniques for Backend Development
a. Predictive Analytics for Resource Management
 If there’s one thing that every backend developer dreads, it’s unexpected traffic spikes or resource shortages that slow down systems and frustrate users. Imagine launching a new product, only to have your site crash because you didn’t anticipate the sheer volume of visitors. Sounds like a nightmare, right? Well, predictive analytics, powered by machine learning (ML), is here to save the day.
If there’s one thing that every backend developer dreads, it’s unexpected traffic spikes or resource shortages that slow down systems and frustrate users. Imagine launching a new product, only to have your site crash because you didn’t anticipate the sheer volume of visitors. Sounds like a nightmare, right? Well, predictive analytics, powered by machine learning (ML), is here to save the day.
Predictive analytics uses historical data, statistical algorithms, and machine learning techniques to forecast future outcomes. In backend development, this means predicting system needs, user behavior, and resource usage before it becomes a problem. So, how does it work, and why is it so crucial for resource management? Let’s dive into this game-changing technique.
i. The Power of Prediction: How It Works
In simple terms, predictive analytics is like having a crystal ball for your backend system. It doesn’t just rely on past data; it analyzes patterns and trends to forecast future events. For instance, if you’re running an online store, predictive analytics can look at data from previous years to estimate the traffic spike during Black Friday or Cyber Monday. It will predict how many users are likely to visit the site, what products they might buy, and even the load on your servers at peak times. This allows you to allocate resources (like bandwidth, CPU, and memory) ahead of time to ensure a smooth user experience, without any lag or crashes.
ii. Forecasting Resource Needs
In backend systems, resource management is a fine art. You need enough servers to handle your site’s traffic, but not too many that you’re paying for unnecessary infrastructure. Traditional resource management often involves manual scaling based on experience, intuition, or guesswork. But this can lead to over-provisioning (wasting resources) or under-provisioning (leading to downtime). Predictive analytics removes the guesswork and gives you data-driven insights into exactly how many resources you’ll need.
How It Works:
- Data Collection: Predictive analytics starts by gathering historical data—everything from system resource usage (like CPU and RAM) to traffic spikes, user behavior, and seasonal patterns.
- Model Training: ML models are trained on this data to detect patterns and correlations. For example, if your website experiences a spike in traffic every weekend, the model will learn this trend.
- Prediction: Based on these patterns, the model can predict future demands, such as when the next spike will occur, how much traffic will come in, and how much server capacity will be needed.
Pro Tip: You can even use predictive analytics for proactive performance monitoring. If your server’s load is trending towards a threshold, the system can automatically adjust resources without you lifting a finger!
iii. Real-World Applications: How It’s Used in Backend Systems
- E-Commerce Platforms:
For online stores, predicting when and where customers will flock to the site can make all the difference. Predictive analytics can estimate sales spikes during holidays, special events, or product launches. For example, an e-commerce website might experience a massive surge in traffic when a popular product goes on sale. By forecasting this spike, the backend system can scale resources (like additional servers or cloud infrastructure) automatically, ensuring that the website remains operational and responsive. Without predictive analytics, the site could crash under the heavy load, costing the business sales and damaging its reputation.
- Streaming Services:
Streaming platforms like Netflix, Hulu, and Spotify experience fluctuating demand based on factors such as the release of new content or the time of day. With predictive analytics, these services can forecast user demand in real-time, ensuring that they have enough bandwidth and server power to deliver uninterrupted streaming experiences. This is especially important during peak times, like when a new season of a popular show drops. By using predictive analytics, streaming services can allocate server resources more efficiently, avoiding slow buffering times and keeping users happy.
- Social Media Platforms:
Social media platforms such as Facebook or Instagram rely heavily on real-time data. Predictive analytics allows these platforms to anticipate server loads based on events like viral posts, live streams, or sudden news events. Imagine a huge spike in traffic when a celebrity posts something trending. Predictive analytics helps the platform allocate resources accordingly, ensuring seamless user experience and preventing downtime during high-traffic periods.
iv. How It Improves Efficiency and Cost-Effectiveness
One of the most significant benefits of predictive analytics for resource management is the ability to increase efficiency and reduce costs. With traditional systems, you may have to over-provision your resources to account for worst-case scenarios. But with predictive analytics, you can more accurately predict demand, meaning you only need to scale your resources when necessary.
Cost-Effectiveness Example:
Let’s say you’re running a cloud-based service that offers file storage. By using predictive analytics, you can predict when usage will be low, allowing you to scale down your resources and save money. Alternatively, when usage spikes, the system can automatically scale up resources to accommodate the increase in demand. Without predictive analytics, you might have to keep a larger number of servers running at all times to be on the safe side—leading to higher costs.
v. Enhancing User Experience
Imagine you’re visiting a website, and suddenly, it takes forever to load. Frustrating, right? Predictive analytics can help prevent this by ensuring that backend resources are always available when needed. By predicting future traffic and scaling resources accordingly, predictive analytics helps ensure smooth, responsive websites.
Additionally, predictive analytics can anticipate user needs by analyzing browsing patterns. For example, if a user regularly visits certain pages or makes specific types of purchases, the backend system can preload relevant data, making the experience faster and more personalized.
vi. Predicting Infrastructure Failures
One of the most impressive uses of predictive analytics in backend systems is its ability to predict hardware failures. Systems can monitor server health and predict when a failure might occur based on historical performance data. If predictive analytics detects an impending failure, the system can either alert the developer or automatically switch to a backup system, preventing downtime and loss of service. This proactive approach reduces the need for costly emergency fixes and downtime.
vii. Future-Proofing Your Backend with Predictive Analytics
As businesses grow and data volumes increase, it’s no longer enough to react to issues as they arise. Predictive analytics equips backend systems with the foresight to stay ahead of the curve. It helps backend developers make data-driven decisions, ensuring that their systems can handle future challenges with ease. As the complexity of backend systems grows, predictive analytics will become even more essential for maintaining optimal performance.
viii. Wrapping It Up: Why Predictive Analytics Is a Must-Have for Backend Development
Predictive analytics is no longer a luxury for backend development—it’s a necessity. By forecasting traffic spikes, resource needs, and potential failures, it helps ensure that systems run efficiently and cost-effectively. Whether it’s improving user experience, anticipating infrastructure failures, or reducing costs, predictive analytics makes backend systems smarter, faster, and more reliable.
Machine learning-powered predictive analytics is transforming how we manage backend systems, providing the foresight to proactively address issues before they escalate. As data grows and technology advances, predictive analytics will continue to be an indispensable tool for backend developers and businesses alike.
b. Anomaly Detection in System Logs
 When you’re building or managing a backend system, you’re constantly dealing with massive amounts of data. Servers churn through logs faster than you can blink, and these logs are invaluable for keeping your system running smoothly. They tell you what’s happening behind the scenes—tracking errors, server performance, and system activities. But what happens when something unusual occurs in these logs? What if an anomaly—a sudden spike in traffic, a weird request, or an error that wasn’t part of the plan—appears? You may not have the time or resources to sift through these logs manually. And that’s where machine learning-powered anomaly detection steps in.
When you’re building or managing a backend system, you’re constantly dealing with massive amounts of data. Servers churn through logs faster than you can blink, and these logs are invaluable for keeping your system running smoothly. They tell you what’s happening behind the scenes—tracking errors, server performance, and system activities. But what happens when something unusual occurs in these logs? What if an anomaly—a sudden spike in traffic, a weird request, or an error that wasn’t part of the plan—appears? You may not have the time or resources to sift through these logs manually. And that’s where machine learning-powered anomaly detection steps in.
Anomaly detection is like having a digital detective watching your system 24/7, looking for anything that doesn’t belong. It analyzes your logs in real time, automatically identifying outliers or unexpected patterns that could signal problems like security breaches, bugs, or inefficiencies. Think of it as your personal watchdog, tirelessly scanning for anything unusual, so you don’t have to. Let’s break down why anomaly detection is so crucial in backend development and how it can help save time, resources, and—most importantly—your sanity.
i. What is Anomaly Detection in System Logs?
At its core, anomaly detection involves using machine learning algorithms to identify patterns in data and then flagging any data points that deviate from these patterns. When applied to system logs, anomaly detection algorithms can spot outliers, errors, or unexpected events that could indicate potential issues in your backend system.
For instance, let’s say your server is running fine most of the time, but suddenly, the log shows a massive spike in error messages or unusual user activity. This could be an indication of a problem, like a security vulnerability being exploited or a bug causing unexpected behavior. Instead of waiting for these issues to escalate, anomaly detection algorithms can catch them early and alert you to take action before the situation becomes critical.
ii. How Does Anomaly Detection Work in Backend Systems?
Anomaly detection relies on machine learning to understand what “normal” looks like for your backend system. Once the model is trained with historical data, it can spot the anomalies in real-time logs by comparing new data against the established norm.
- Data Collection: The first step in anomaly detection is collecting system logs. These logs can contain a wide variety of data, such as server requests, errors, API calls, and even user behavior. The more comprehensive the dataset, the better the model will perform.
- Model Training: Machine learning models are then trained on this data. This means the algorithm learns what “normal” activity looks like—such as typical request rates, usual error patterns, or expected server response times.
- Real-Time Monitoring: Once the model has been trained, it’s deployed to monitor incoming system logs in real time. As new logs come in, the algorithm checks for deviations from the learned patterns. If something unusual happens—like a sudden spike in errors or an unexpected user behavior pattern—the system flags this as an anomaly and sends an alert to the backend team.
Pro Tip: Some anomaly detection models use techniques like clustering or neural networks to identify outliers. Clustering groups similar data points together and flags anything that doesn’t fit the group as an anomaly. Neural networks, on the other hand, learn intricate patterns in data, allowing them to detect more complex anomalies.
iii. Types of Anomalies Detected in System Logs
Anomaly detection isn’t a one-size-fits-all solution. It can be customized to detect various types of anomalies, depending on what you’re looking for. Below are some common types of anomalies that are typically flagged in system logs:
- Statistical Anomalies: These anomalies occur when the data points are far from the mean or expected value. For example, a sudden spike in server error rates or an unexpected increase in database queries might be flagged as a statistical anomaly.
- Contextual Anomalies: Contextual anomalies arise when a certain event seems unusual within a specific context but might not be out of the ordinary when viewed over a longer period or in a different context. For example, a spike in traffic could be expected on a major holiday, but it might be an anomaly if it happens at a random time without any promotional events.
- Collective Anomalies: This type of anomaly occurs when multiple data points, when taken together, deviate from the norm. It could indicate a larger system-wide problem, like a DDoS attack or a performance bottleneck in your backend infrastructure.
iv. Benefits of Anomaly Detection in Backend Development
- Proactive Issue Resolution: With machine learning-powered anomaly detection, you’re not just reacting to problems as they arise—you’re staying ahead of the curve. Early detection of issues like system crashes, security breaches, or performance bottlenecks helps you address problems before they snowball into major incidents.
- Enhanced Security: In the world of backend systems, security is a constant concern. Anomaly detection is particularly useful for spotting abnormal patterns that could indicate a potential security threat. For instance, unusual login attempts or an unexpected surge in API requests might suggest a brute-force attack or other malicious activity. By flagging these anomalies early, you can protect your system from cyber threats.
- Improved System Efficiency: Anomalies often highlight inefficiencies or bugs that can affect system performance. For example, a sudden surge in memory usage might be a sign of a memory leak, and an unusual increase in database queries could point to an inefficient query or an issue in your application’s code. By detecting these anomalies early, you can optimize your backend system to run more efficiently.
- Reduced Downtime and Cost: Every minute your backend system is down or not performing optimally, it costs you. Anomaly detection helps reduce downtime by catching issues before they escalate into full-blown outages. Additionally, by identifying inefficiencies early on, you can save on resources and reduce the need for costly fixes.
v. How Anomaly Detection Improves Monitoring and Troubleshooting
Let’s face it—debugging a backend system can feel like finding a needle in a haystack. With so many logs coming in at once, pinpointing the root cause of an issue can take hours or even days. But anomaly detection changes the game.
By flagging unusual patterns as they appear, anomaly detection helps developers quickly identify the source of the problem. Rather than scrolling through countless lines of logs, you can focus on the anomalies flagged by the system and investigate those areas directly. This targeted approach makes monitoring and troubleshooting much more efficient, saving both time and resources.
vi. Real-World Examples of Anomaly Detection
- Security Breaches: Let’s say your system logs show a sudden surge in failed login attempts. Traditional methods might not catch this in time, but anomaly detection algorithms would immediately flag this as an anomaly. This could be an indication of a brute-force attack, and your system can react quickly to lock down the affected accounts or block the source of the attack.
- Database Performance Issues: Imagine that your backend team notices a slowdown in database queries. By using anomaly detection, the system might highlight a specific query that’s suddenly taking up much more time than usual. This allows the team to quickly address the issue before it causes a bigger performance bottleneck.
- Server Failures: Server failures often begin with subtle signs, such as increased error rates or high resource usage. With anomaly detection, these signs are flagged early, allowing backend teams to respond to potential issues before the server goes down.
vii. Conclusion: The Importance of Anomaly Detection in Backend Development
In the fast-paced world of backend development, staying ahead of potential issues is key to maintaining a healthy and efficient system. Anomaly detection offers a way to identify problems before they become critical, improving security, system performance, and overall user experience. With machine learning-powered algorithms keeping a constant watch on your system logs, you can spend less time reacting to issues and more time optimizing your backend for success.
c. Recommendation Systems for API Design
 Ah, the good ol’ recommendation system. We’ve all encountered them—whether it’s Netflix suggesting the next binge-worthy series, Amazon recommending that must-have gadget, or Spotify offering a curated playlist based on our mood. While these systems are all about giving users a more personalized experience, they also have a key role in backend development, especially when it comes to optimizing API design. If your API can’t provide fast, personalized recommendations, then what’s the point, right? So, let’s dive into how recommendation systems are revolutionizing API design, making it smarter, faster, and more in tune with what users want.
Ah, the good ol’ recommendation system. We’ve all encountered them—whether it’s Netflix suggesting the next binge-worthy series, Amazon recommending that must-have gadget, or Spotify offering a curated playlist based on our mood. While these systems are all about giving users a more personalized experience, they also have a key role in backend development, especially when it comes to optimizing API design. If your API can’t provide fast, personalized recommendations, then what’s the point, right? So, let’s dive into how recommendation systems are revolutionizing API design, making it smarter, faster, and more in tune with what users want.
I. What is a Recommendation System and Why Does it Matter?
At its core, a recommendation system is a machine learning-powered tool that predicts what a user might like based on their past behavior, preferences, and interactions. Imagine having a digital personal assistant that knows you so well, it can suggest the best products, movies, songs, or even news articles based on what you’ve previously enjoyed.
In backend development, recommendation systems play a crucial role in making APIs smarter. APIs that incorporate recommendation systems can provide users with a personalized experience, whether that’s suggesting products on an e-commerce platform or curating a list of articles on a news site. They analyze large amounts of data, like past user interactions, preferences, and behavior, and generate predictions or recommendations. The better the recommendation, the more engaged users will be.
But here’s the kicker: for recommendation systems to work effectively in backend development, they need to be incorporated into well-designed APIs. APIs are like the bridge that connects all the data to the front-end application—without a solid API, the recommendation system can’t do its magic.
II. How Recommendation Systems Work in Backend APIs
Now that we know what recommendation systems are, let’s explore how they actually work behind the scenes, especially in the context of APIs.
- Data Collection: For a recommendation system to be effective, it needs access to user data. This includes historical data like what products a user has viewed or purchased, what movies they’ve watched, or what music they’ve listened to. The more data it has, the more accurate the recommendations will be.
- Data Processing: Once the data is collected, the API will need to preprocess it. This is where the magic of machine learning kicks in—using algorithms like collaborative filtering, content-based filtering, or hybrid models to identify patterns in the data. Collaborative filtering, for example, looks for users with similar preferences and recommends items that those users have liked. Content-based filtering, on the other hand, uses item features (like genre, author, or brand) to make suggestions based on what the user has liked before.
- Recommendation Generation: After the data has been processed, the recommendation system generates a list of suggestions. The backend API uses this output to send personalized content to the front end. The API then formats the data and ensures it’s delivered in a way that the client can easily display it to the user.
- Real-Time Updates: One of the key aspects of modern recommendation systems is their ability to make real-time recommendations. As users interact with the API, their preferences change, and the system adapts. Real-time data allows the recommendation engine to offer fresh, relevant suggestions based on current behavior, not just historical data.
III. Types of Recommendation Systems
Recommendation systems come in various flavors, each with its own unique approach. Understanding the different types can help backend developers choose the right one for their API design.
- Collaborative Filtering: This method makes recommendations based on the past behaviors of other users. The assumption is that users who have similar tastes will like the same items. For example, if user A likes products 1, 2, and 3, and user B likes 2, 3, and 4, the system will recommend product 4 to user A because they share similar preferences.
- Content-Based Filtering: In contrast to collaborative filtering, content-based filtering uses the features of the items themselves (like categories, tags, or descriptions). If you’ve watched a lot of action movies, the recommendation system will suggest more action movies based on those similar attributes.
- Hybrid Models: A hybrid recommendation system combines multiple approaches—collaborative filtering and content-based filtering, for example. This gives the system the flexibility to make more accurate predictions by leveraging the strengths of both methods.
- Knowledge-Based Systems: These systems are based on explicit user preferences. For instance, in a travel API, if a user selects “budget-friendly” and “beach destinations,” the system will prioritize those attributes while recommending hotels or vacation packages.
IV. Benefits of Incorporating Recommendation Systems into API Design
Now, let’s talk about why you should care about recommendation systems when designing an API. Here are some of the key benefits:
- Personalized User Experience: The biggest advantage of recommendation systems is that they offer personalized experiences for users. When a backend API suggests products, content, or services based on individual preferences, users feel more engaged and are more likely to continue using the service.
- Increased Engagement and Retention: Personalized recommendations can significantly increase user engagement. For example, if Netflix keeps suggesting shows you actually want to watch, you’re more likely to stick around. In the same way, personalized product recommendations on an e-commerce site encourage users to make more purchases, increasing customer retention.
- Improved Decision-Making: Recommendation systems help users make decisions faster. Instead of scrolling endlessly through thousands of items, users are shown what they’re most likely to enjoy, which makes the decision-making process quicker and less frustrating. In backend development, this means a more efficient API design that saves users time and effort.
- Increased Revenue: Personalized recommendations aren’t just great for users—they’re also fantastic for businesses. When customers are presented with products or services they’re more likely to buy, businesses see an uptick in revenue. It’s a win-win!
V. Challenges of Implementing Recommendation Systems in API Design
While the benefits of recommendation systems are clear, implementing them within an API design can be tricky. Here are some common challenges backend developers might face:
- Data Quality and Quantity: The more data the recommendation system has, the better the suggestions. However, not all data is created equal. If the data is incomplete, noisy, or biased, the recommendations might be inaccurate, leading to frustrated users. Collecting high-quality data is critical for a successful recommendation system.
- Cold Start Problem: New users or new items in the system can pose a problem. If there isn’t enough historical data to base recommendations on, the system can’t provide personalized suggestions. Solving the cold start problem requires creative approaches, such as using content-based filtering for new items or gathering more explicit data from users when they first sign up.
- Scalability: As your API grows and more users interact with your system, it’s crucial that your recommendation system can scale. A system that works well for a few hundred users might struggle to handle millions. Ensuring that your recommendation engine can scale is key to providing fast and accurate recommendations to all users.
VI. Real-World Examples of APIs with Recommendation Systems
Let’s look at a few real-world examples of how recommendation systems are integrated into APIs:
- E-commerce APIs: Companies like Amazon use recommendation systems to suggest products based on user behavior and preferences. Their APIs are designed to quickly provide these suggestions as users browse the site, leading to higher sales and a more personalized shopping experience.
- Music Streaming APIs: Spotify uses collaborative filtering to recommend songs based on the listening history of users. Their API delivers curated playlists and song recommendations, helping users discover new music that aligns with their tastes.
- Video Streaming APIs: Netflix is a classic example of a recommendation engine in action. By analyzing viewing history and preferences, their API can suggest movies and TV shows that are more likely to resonate with users.
d. Natural Language Processing (NLP) for Automation
 If you’ve ever had a conversation with Siri or Alexa, or seen a chatbot answering customer queries online, you’ve encountered Natural Language Processing (NLP) in action. But NLP isn’t just for fancy voice assistants—it’s also a game-changer in backend development, especially when it comes to automation. Imagine an API that not only understands user input but also interprets and responds in ways that feel human. That’s the magic of NLP! Let’s dig into how this technology is transforming backend systems, enabling smarter automation, and making user interactions more efficient.
If you’ve ever had a conversation with Siri or Alexa, or seen a chatbot answering customer queries online, you’ve encountered Natural Language Processing (NLP) in action. But NLP isn’t just for fancy voice assistants—it’s also a game-changer in backend development, especially when it comes to automation. Imagine an API that not only understands user input but also interprets and responds in ways that feel human. That’s the magic of NLP! Let’s dig into how this technology is transforming backend systems, enabling smarter automation, and making user interactions more efficient.
I. What is Natural Language Processing (NLP)?
Before diving into how NLP fits into backend automation, let’s first understand what NLP is all about. NLP is a branch of artificial intelligence (AI) that enables machines to understand, interpret, and respond to human language in a meaningful way. It’s about breaking down human speech or text into data that a computer can analyze, process, and understand.
Think of it like this: whenever you talk to a voice assistant or type a query into Google, NLP is at work behind the scenes. It’s the technology that converts your words into something a computer can process, understand, and respond to. In backend systems, NLP plays a pivotal role in automating tasks that previously required human intervention.
For instance, NLP helps backends interpret unstructured data, such as customer emails, social media comments, and even voice inputs. Instead of relying on rigid commands, NLP-powered systems can handle natural conversations and text—making automation more flexible and efficient.
II. How NLP Powers Automation in Backend Development
NLP’s role in automation is huge, especially in backend systems. Here’s a breakdown of how NLP can turbocharge automation:
- Automating Customer Support with Chatbots:
Chatbots are probably the most common example of NLP in action. Instead of a human answering every single customer query, NLP allows chatbots to interpret and respond to customer inquiries automatically. The backend API integrates the chatbot with NLP algorithms to understand the intent behind user queries, interpret the data, and provide accurate responses without human intervention.
Example: Imagine a customer texting a company’s customer service bot, saying, “I want to cancel my subscription.” NLP interprets the request, triggers the appropriate automation, and sends a cancellation confirmation without the need for a human agent.
- Text Classification for Automation:
Text classification is another area where NLP shines. It involves categorizing text data into predefined categories. In backend systems, this can be used to automate tasks like categorizing customer support tickets, sorting emails, or even analyzing social media posts. By automatically tagging and sorting content, NLP helps systems streamline processes, prioritize important tasks, and cut down manual workloads.
Example: Imagine you’re a backend developer building an API for an e-commerce platform. With NLP, the system can automatically categorize customer feedback into groups like “product issue,” “shipping concern,” or “positive review,” allowing your system to route the issues to the correct department without human intervention.
- Sentiment Analysis for Decision Making:
Sentiment analysis is another powerful tool that NLP offers. It allows backend systems to automatically analyze the sentiment behind a piece of text—whether it’s positive, negative, or neutral. By analyzing customer reviews, social media posts, or support tickets, sentiment analysis can help businesses automate decision-making and prioritize tasks based on urgency.
Example: Let’s say you’re running a backend system that handles customer feedback for a product. Using sentiment analysis, the system can automatically identify whether a review is positive or negative. If the review is negative, it might trigger an automated follow-up to resolve the issue, while positive reviews can be logged and stored for future use.
- Speech Recognition for Voice-Activated Automation:
Speech recognition, an NLP application, is increasingly popular in automation. Voice assistants like Google Assistant or Amazon Alexa use NLP to interpret spoken language, enabling users to control devices or get information through voice commands. On the backend, NLP converts voice inputs into text, and then the system processes this text to trigger automated actions.
Example: Picture a backend system for a home automation device. When a user says, “Turn off the lights in the living room,” NLP interprets the command, the backend processes it, and the lights are turned off—all without human intervention.
III. Key Benefits of Using NLP for Automation in Backend Development
Now that we’ve explored how NLP powers automation, let’s talk about the benefits it brings to backend development.
- Enhanced User Experience:
The ability of NLP systems to understand natural language allows users to interact with machines more intuitively. Whether it’s chatting with a bot, sending a voice command, or asking a question in plain text, NLP ensures that interactions feel natural and efficient. By automating responses based on user input, backend systems become more user-friendly and reduce the need for human agents.
Pro Tip: The more accurate your NLP system, the more seamless and engaging the user experience becomes. Users don’t want to feel like they’re talking to a robot—they want smooth, natural interactions!
- Faster and More Efficient Automation:
NLP-based automation can process a massive amount of data quickly, far beyond human capabilities. Instead of relying on manual intervention to categorize data, answer queries, or perform repetitive tasks, NLP can handle all of these processes automatically. This leads to faster turnaround times and greater efficiency in backend operations.
Example: Instead of having customer support agents manually sorting through emails and tickets, an NLP-powered backend can automatically categorize and prioritize them. This cuts down on processing time and allows agents to focus on more complex issues.
- Cost Savings:
By automating tasks like customer service, data categorization, and sentiment analysis, businesses can reduce the need for human intervention in repetitive tasks. This translates to cost savings, as businesses don’t have to hire as many staff members to handle basic queries or data processing.
Fun Fact: It’s estimated that businesses can save up to 30% in operational costs by automating tasks with NLP-powered systems!
- Scalability:
As businesses grow, the volume of interactions, customer queries, and content data increases. NLP systems allow backend processes to scale automatically without the need for hiring additional human resources. Whether it’s handling millions of customer inquiries or processing large amounts of text data, NLP can handle it all at scale.
Example: An NLP-powered chatbot can seamlessly handle a surge of customer queries during a sale, while still providing timely responses to every customer.
IV. Real-World Applications of NLP in Backend Automation
Let’s take a look at some real-world examples of NLP being used for backend automation.
- E-Commerce Automation:
Many e-commerce platforms use NLP to automate product recommendations, customer service, and even product reviews. By understanding customer queries and automatically routing them to the appropriate service, these platforms can provide an efficient and personalized shopping experience.
- Healthcare Automation:
NLP is increasingly used in healthcare systems to automate the processing of medical records, clinical notes, and patient feedback. This helps doctors and medical professionals streamline their workflows and focus more on patient care.
- Customer Support Chatbots:
Many companies integrate NLP-powered chatbots into their customer support systems. These bots can answer a wide range of queries, provide troubleshooting steps, and escalate issues to human agents when needed. By automating routine customer interactions, businesses can save time and money while improving customer satisfaction.
V. Challenges of Using NLP in Backend Automation
Despite its advantages, implementing NLP for automation can come with some challenges:
- Language Complexity:
Human language is inherently complex and often ambiguous. NLP systems may struggle to understand slang, idiomatic expressions, or regional dialects, leading to misinterpretations. To improve accuracy, NLP models need to be trained on diverse data and continuously updated.
- Data Privacy Concerns:
When using NLP to process sensitive data like customer queries or healthcare records, businesses need to ensure that data privacy is maintained. This can be particularly challenging when handling personal or confidential information.
- Training Data Requirements:
For NLP to be effective, it requires large amounts of high-quality training data. Gathering this data can be time-consuming and expensive, and poor-quality data can lead to inaccurate results.
In the world of backend development, NLP is not just a buzzword—it’s a powerhouse that drives smarter automation, faster response times, and better user experiences. By incorporating NLP into backend systems, developers can build solutions that not only understand human language but also act upon it, reducing manual work and improving operational efficiency. So, if you’re looking to elevate your backend development game, it’s time to embrace NLP and let automation do the heavy lifting!
e. Reinforcement Learning for Dynamic Task Scheduling
 When you think about how complex systems handle multiple tasks at the same time—whether it’s running a cloud service or managing a large e-commerce platform—you might wonder how these systems prioritize and schedule tasks efficiently. Well, that’s where Reinforcement Learning (RL) comes in! It’s like giving your backend system the ability to learn from experience and make intelligent decisions about task scheduling based on changing conditions.
When you think about how complex systems handle multiple tasks at the same time—whether it’s running a cloud service or managing a large e-commerce platform—you might wonder how these systems prioritize and schedule tasks efficiently. Well, that’s where Reinforcement Learning (RL) comes in! It’s like giving your backend system the ability to learn from experience and make intelligent decisions about task scheduling based on changing conditions.
In backend development, dynamic task scheduling is critical because systems often face the need to balance multiple tasks, deal with changing workloads, and ensure that resources are used efficiently. Reinforcement Learning provides a way to tackle these challenges by allowing systems to learn optimal scheduling strategies over time, just like how a self-driving car learns to drive better the more it experiences different driving conditions.
Let’s dive deeper into how RL is transforming backend task scheduling and how you can use it to supercharge your systems!
I. What is Reinforcement Learning (RL)?
Before jumping into the role of RL in dynamic task scheduling, let’s first break down what RL is. Reinforcement Learning is a type of machine learning where an agent (think of it as a virtual decision-maker) learns by interacting with an environment, receiving feedback (rewards or penalties), and improving its actions to achieve a goal.
In simpler terms, RL is like a video game. When you play a game, you try different strategies to score points (rewards) and avoid losing lives (penalties). The more you play, the better you get at the game because you learn from your mistakes and adjust your strategies.
In backend development, the “agent” is the system managing tasks, and the “environment” is the set of tasks and available resources. The system makes scheduling decisions, receives feedback (like whether a task was completed on time or resources were overused), and adjusts its strategy for future tasks.
II. How Reinforcement Learning Enhances Dynamic Task Scheduling
Task scheduling is a critical function in backend systems, especially when managing tasks like processing data requests, running background processes, or handling user interactions. Traditional scheduling techniques often rely on static rules or simple priority-based systems, but as tasks become more complex and resource demands fluctuate, these methods can lead to inefficiencies.
Here’s where RL steps in to make task scheduling smarter and more adaptive:
- Optimizing Resource Allocation:
In any backend system, there are limited resources (like CPU, memory, or network bandwidth) that need to be distributed across multiple tasks. RL helps systems figure out the best way to allocate resources to tasks based on past experiences. It learns to allocate resources dynamically, ensuring that tasks are completed on time without overwhelming the system.
Example: Imagine a cloud service handling multiple customer requests. Using RL, the system can learn how to allocate bandwidth efficiently—prioritizing critical tasks (like payments or login requests) while ensuring that less important tasks (like generating reports) don’t consume too much bandwidth.
- Learning Optimal Task Sequences:
Some tasks depend on others. For example, in a data processing pipeline, one task might need to finish before another can start. RL can optimize the order of task execution to ensure that each task is performed at the right time, with the least amount of delay.
Example: Consider a backend system processing customer orders. With RL, the system can learn the best sequence for fulfilling orders—starting with high-priority orders, then processing routine orders while keeping track of resource usage to avoid bottlenecks.
- Adapting to Changing Workloads:
One of the key benefits of RL is its ability to adapt. Unlike static scheduling methods, RL doesn’t just follow predefined rules—it continuously learns and adjusts based on changing workloads. Whether it’s handling a sudden spike in traffic or an unexpected server failure, RL allows the backend system to adapt and maintain performance without manual intervention.
Example: During peak shopping seasons, like Black Friday, a backend system might experience a sudden spike in user traffic. With RL, the system can learn from past traffic patterns and adjust its scheduling strategies in real-time, ensuring that tasks like inventory updates and payment processing remain smooth, even under heavy load.
III. Benefits of Using Reinforcement Learning in Task Scheduling
Now that we understand how RL enhances task scheduling, let’s explore the key benefits it brings to backend systems.
- Efficiency and Resource Optimization:
One of the most significant advantages of RL is its ability to optimize resource usage. By continuously learning from its environment, an RL-powered backend system can ensure that resources are allocated in the most efficient way possible. This reduces waste and maximizes throughput.
Pro Tip: The more data the RL system processes, the better it gets at predicting resource usage. Over time, it becomes an expert in task scheduling, reducing the chances of overloading the system.
- Scalability:
As backend systems scale and the number of tasks grows, managing them manually or with static rules becomes increasingly difficult. RL offers a scalable solution by automatically adjusting to changes in task volume and system capacity. This means that whether your system handles 100 tasks a day or 100,000, RL will adapt to ensure everything runs smoothly.
Example: In a large-scale e-commerce platform, RL can dynamically schedule tasks such as payment processing, inventory updates, and order tracking based on real-time demand, ensuring the system can scale without crashing under heavy loads.
- Improved Task Completion Times:
RL helps to minimize delays by learning the optimal task sequences and resource allocation strategies. As a result, tasks are completed faster, improving overall system performance. This is especially important in systems where speed is critical, such as in real-time data processing or time-sensitive transactions.
Fun Fact: Some companies have reported a 30-40% reduction in task completion times after integrating RL into their backend scheduling systems!
- Adaptability to Changing Conditions:
RL systems are highly adaptable. They learn from new experiences and adjust their strategies accordingly. If the system’s workload changes, or if there’s a sudden change in available resources (such as server downtime or a network failure), RL can quickly adapt to ensure tasks are still completed efficiently.
Example: Let’s say a backend system handles an e-learning platform. If students are suddenly uploading videos or accessing resources in large numbers, the RL system can adapt to prioritize those requests and delay non-urgent tasks like updating content.
IV. Real-World Applications of Reinforcement Learning for Task Scheduling
Reinforcement Learning isn’t just a theoretical concept—it’s already being used in various industries to improve backend task scheduling. Here are some real-world examples:
- Cloud Computing:
In cloud services, dynamic task scheduling is crucial to ensure efficient resource allocation across virtual machines (VMs) and servers. RL is used to dynamically allocate resources based on demand, preventing over-provisioning (which wastes resources) and under-provisioning (which causes delays or failures).
- Data Centers:
Data centers often face challenges with load balancing and task scheduling. RL can help automate the process of allocating workloads to servers, optimizing energy consumption, and ensuring that resources are used efficiently across the entire data center.
- Robotics and Autonomous Systems:
In robotics, task scheduling plays a key role in determining which tasks the robot should prioritize. RL allows robots to learn from their environment, adjust their behavior in real-time, and handle tasks more efficiently. For example, an autonomous delivery robot may need to decide whether to pick up a package first or deliver an existing one.
V. Challenges and Considerations
While RL is a powerful tool for dynamic task scheduling, it does come with its own set of challenges:
- Training Time:
RL systems require a significant amount of training data to learn optimal strategies. This means that the system may take some time to become proficient at scheduling tasks, especially in complex environments.
- Complexity:
Implementing RL for task scheduling can be complex, particularly when dealing with large-scale systems or diverse types of tasks. The algorithm needs to be carefully designed and tested to ensure that it performs as expected in real-world scenarios.
- Data Dependency:
The performance of RL models is highly dependent on the quality and quantity of data. Without sufficient data, RL models may struggle to learn optimal strategies, leading to suboptimal task scheduling.
Reinforcement Learning is transforming the way backend systems handle task scheduling. By making systems more adaptable, efficient, and intelligent, RL allows developers to create solutions that can scale, optimize resources, and improve performance over time. So, if you’re looking to level up your backend development, integrating RL into your task scheduling process is a smart move!
f. Machine Learning for Security Enhancement
 In the fast-paced digital world, where cyber threats are evolving at lightning speed, ensuring the security of backend systems has become more critical than ever. From protecting sensitive data to preventing unauthorized access, security has always been a priority for any system. But, just as technology advances, so do the tactics of malicious actors. So, how do we keep up? Enter Machine Learning (ML). ML, with its ability to learn from data and predict future threats, is a game-changer in backend security.
In the fast-paced digital world, where cyber threats are evolving at lightning speed, ensuring the security of backend systems has become more critical than ever. From protecting sensitive data to preventing unauthorized access, security has always been a priority for any system. But, just as technology advances, so do the tactics of malicious actors. So, how do we keep up? Enter Machine Learning (ML). ML, with its ability to learn from data and predict future threats, is a game-changer in backend security.
Imagine you have a security system that not only reacts to known threats but also learns from new, previously unseen ones and adapts its defenses in real time. That’s exactly what ML brings to the table. By implementing ML in backend development, businesses can proactively guard against attacks like never before. Let’s explore how ML is revolutionizing backend security and how it can protect your systems from a wide range of security vulnerabilities.
I. Why is Security Important in Backend Development?
Before diving into how ML helps, it’s essential to understand why security is so vital in backend systems. A backend system is like the engine of a car; it’s where everything happens. When users interact with an app, their requests are processed in the backend, and sensitive information (like passwords, payment details, or personal data) often flows through it.
If the backend system is compromised, it could lead to data breaches, loss of user trust, financial losses, or even legal consequences. That’s why safeguarding the backend infrastructure is critical. Traditional security methods, like firewalls or antivirus software, are useful, but they can’t always handle the complexity or unpredictability of modern cyber threats. That’s where ML comes in—its ability to learn, predict, and adapt makes it a powerful tool for reinforcing backend security.
II. How Machine Learning Enhances Backend Security
Machine learning enhances backend security by providing systems with the ability to automatically detect threats, respond to them, and learn from past attacks. Traditional security methods are static, meaning they can only react to known threats based on predefined rules. But ML is dynamic—it adapts and improves over time, making backend systems smarter and more resilient.
Let’s explore some specific ways ML boosts backend security:
III. Machine Learning for Threat Detection
One of the most significant ways ML can enhance backend security is by identifying potential threats before they cause harm. By analyzing system logs, traffic patterns, and user behavior, ML models can detect anomalies or suspicious activities in real time.
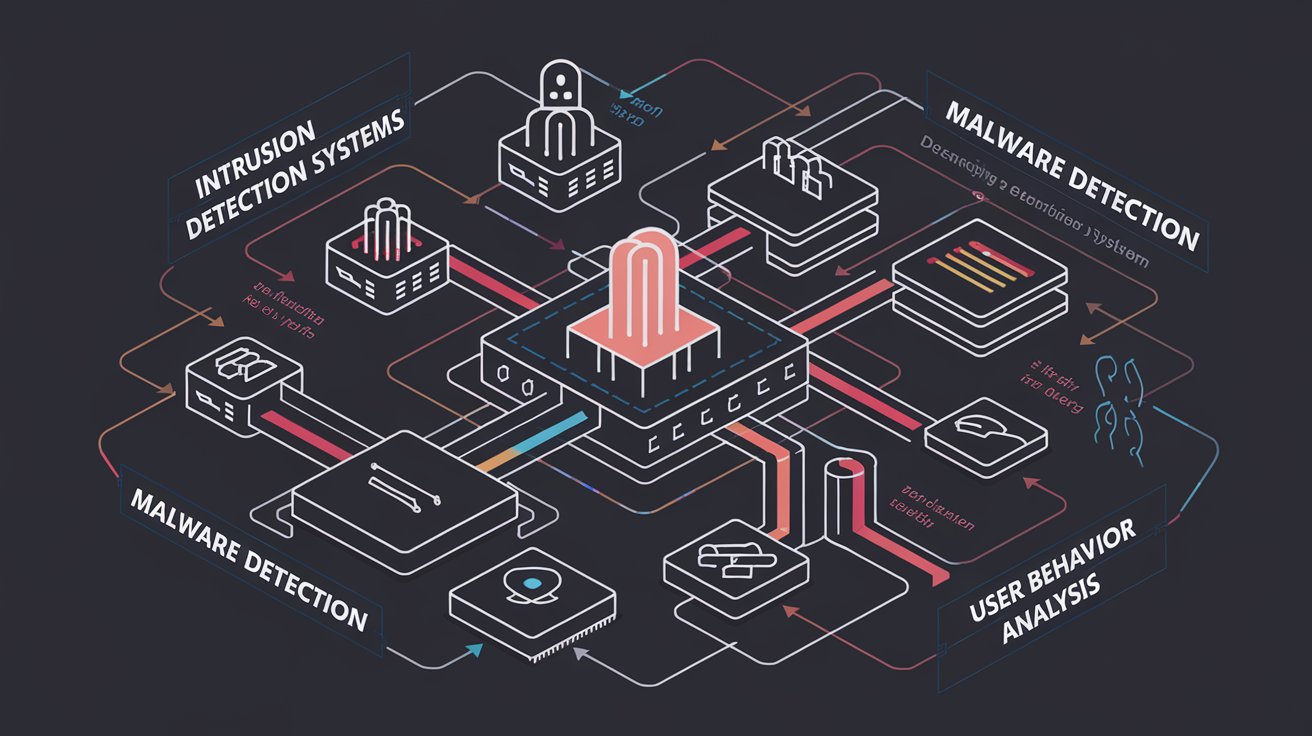
- Intrusion Detection Systems (IDS):
Traditional IDS look for known patterns of malicious activity. However, cyberattacks are constantly evolving, and new techniques are always being developed. ML-based IDS goes a step further by using algorithms that learn from past attack data. Over time, these systems get better at detecting novel or previously unseen attacks.
Example: Imagine a situation where an attacker is trying to brute-force their way into a system by guessing passwords. An ML-based IDS can learn the typical login behavior of users and recognize when an unusual number of failed login attempts occurs, alerting the system of a potential attack.
- Malware Detection:
Malware can take many forms, such as viruses, worms, or Trojans. ML-powered systems can analyze the behavior of files and processes to determine if they’re exhibiting malicious activity. These systems don’t rely on a list of known threats—they look for patterns in file behavior and use this information to identify malware.
Example: Let’s say a backend system is receiving files from external sources. An ML system can analyze the file’s behavior to determine if it is attempting to access sensitive data or propagate itself across the network. If the file exhibits suspicious behavior, the system can block it before it causes any damage.
IV. User Behavior Analytics (UBA) for Threat Prevention
Another powerful application of ML in backend security is User Behavior Analytics (UBA). UBA uses ML to track and analyze user behavior within the system. By establishing a baseline of “normal” user activity, the system can identify deviations that may signal potential security threats, such as unauthorized access or insider threats.
- Anomaly Detection in User Behavior:
ML models can continuously monitor user behavior in the backend, such as login times, access patterns, and frequency of actions. If a user suddenly logs in from a different geographical location or accesses sensitive data they normally don’t, ML can flag this behavior as potentially suspicious.
Example: Imagine a backend system where an employee accesses the company’s financial records every day, but one day, they try to access data outside their usual scope, at a time when they normally wouldn’t be working. An ML model could flag this as a potential security risk, allowing the system to automatically block further access or notify security teams.
- Insider Threat Detection:
While external cyberattacks often get the most attention, insider threats—where employees or contractors misuse their access privileges—are just as dangerous. ML can help detect these threats by identifying unusual activity within the system.
Example: If an employee suddenly downloads large amounts of sensitive data or accesses systems they don’t usually work with, an ML-powered backend system could immediately flag this behavior and take action to prevent data theft or loss.
V. Automating Security Response with ML
Another key advantage of integrating ML into backend security is the ability to automate security responses. Rather than relying solely on human intervention to react to potential threats, ML systems can autonomously take action based on what they’ve learned about potential risks.
- Automated Blocking of Malicious IPs:
If an ML model detects that a particular IP address is associated with malicious activity, such as multiple failed login attempts or suspicious traffic patterns, it can automatically block that IP address in real-time.
- Predictive Security Measures:
ML doesn’t just react to threats—it can also predict potential future threats. By analyzing patterns in data over time, ML systems can forecast where attacks are likely to happen, allowing teams to implement proactive security measures.
VI. Advantages of Machine Learning in Security Enhancement
There are several compelling reasons why integrating ML into backend security is a smart move:
- Real-Time Threat Detection and Response:
ML models can analyze vast amounts of data in real time, allowing them to identify threats and respond before they can do significant damage. Traditional methods may take too long to detect and respond to threats, but ML provides a fast, automated solution.
- Improved Accuracy:
Since ML models learn from data, they can improve their accuracy over time. As they process more data, they become better at detecting threats, reducing the chances of false positives and false negatives.
- Adaptability to Evolving Threats:
Cyberattacks are always evolving. ML systems are dynamic and can adapt to new types of threats, making them more resilient than traditional security tools that may only recognize known attacks.
VII. Real-World Applications of Machine Learning in Security
Many industries are already leveraging the power of ML to enhance security in their backend systems:
- Financial Institutions:
Banks and financial institutions use ML for fraud detection, monitoring transactions in real time to spot unusual activity that might indicate fraudulent transactions. By analyzing transaction patterns, ML systems can identify potential fraudsters and prevent them from accessing accounts.
- Healthcare Industry:
In healthcare, where patient data is highly sensitive, ML models help detect breaches and ensure compliance with privacy regulations such as HIPAA. They can identify anomalous access to patient records, ensuring that only authorized personnel have access.
- E-Commerce Platforms:
E-commerce websites often deal with large amounts of sensitive customer data, such as credit card information. ML models are used to monitor and protect customer transactions, flagging any suspicious activities like account takeovers or payment fraud.
VIII. Challenges and Considerations
Despite its potential, using ML for security enhancement is not without challenges. For instance:
- Data Privacy:
Machine learning models require large amounts of data to function effectively. However, handling sensitive data for security purposes must be done with care, ensuring compliance with privacy laws and regulations.
- Model Training and Maintenance:
To be effective, ML models must be trained on high-quality data. The process of training models can be time-consuming, and the models need regular updates to keep up with new types of threats.
- Complexity:
Integrating ML into security systems requires specialized knowledge and resources. Organizations must ensure they have the expertise to properly deploy and maintain these models.
In conclusion, ML isn’t just a buzzword in backend security—it’s a game-changer. By offering real-time threat detection, predictive capabilities, and automated responses, ML transforms how systems protect themselves against evolving cyber threats. With its ability to continuously learn from data, ML ensures that backend systems can stay one step ahead of attackers, keeping user data safe and secure. So, if you haven’t yet explored how ML can enhance your backend security, now’s the time to start!
g. Automated Machine Learning (AutoML) for Model Deployment
 Machine learning (ML) has certainly come a long way in revolutionizing industries and providing businesses with new opportunities to enhance user experiences, streamline operations, and improve security. But as powerful as machine learning is, there’s still one challenge many organizations face: deploying and maintaining machine learning models in a production environment. The good news? Enter Automated Machine Learning (AutoML), the hero in this story, transforming the way models are deployed and maintained.
Machine learning (ML) has certainly come a long way in revolutionizing industries and providing businesses with new opportunities to enhance user experiences, streamline operations, and improve security. But as powerful as machine learning is, there’s still one challenge many organizations face: deploying and maintaining machine learning models in a production environment. The good news? Enter Automated Machine Learning (AutoML), the hero in this story, transforming the way models are deployed and maintained.
AutoML is a game-changer, allowing businesses to create powerful machine learning models without requiring expert-level knowledge of data science. By automating the time-consuming aspects of model development, like feature selection, model training, and hyperparameter tuning, AutoML enables faster and more efficient model deployment. Let’s dive into how AutoML works and how it is transforming backend development.
I. What is AutoML and Why is It Important?
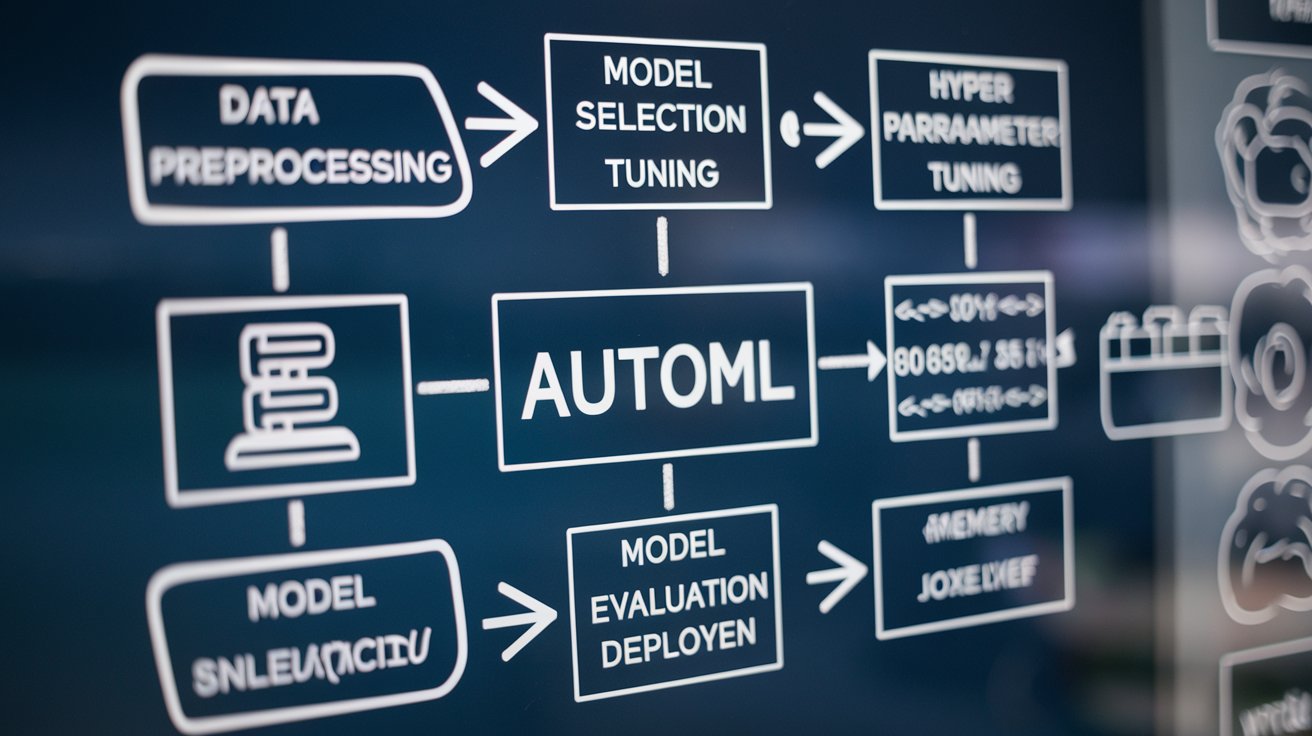
Before we get into the nitty-gritty, let’s take a step back and explore what AutoML really is. In simple terms, Automated Machine Learning refers to the process of automating the entire workflow of machine learning model development, from data preprocessing to model deployment. The goal is to make machine learning accessible to a wider audience, including those without a strong background in data science.
Historically, deploying machine learning models required a deep understanding of algorithms, data processing, and tuning hyperparameters. This complexity could make it difficult for companies without data science teams to leverage the full potential of machine learning. AutoML solves this problem by automating key aspects of the ML workflow, making it easier for businesses to integrate machine learning into their backend systems.
In backend development, where speed, efficiency, and scalability are crucial, AutoML allows developers to quickly deploy machine learning models that can improve processes such as user behavior prediction, recommendation systems, or anomaly detection. By doing so, AutoML reduces the time and effort required for model deployment while still delivering powerful insights.
II. Key Benefits of AutoML for Backend Development
So why is AutoML such a game-changer? Well, let’s explore some of the major benefits it brings to backend development:
- Faster Model Development and Deployment
The process of building a machine learning model can be lengthy and resource-intensive. With AutoML, many steps—like data preprocessing, model selection, and hyperparameter tuning—are automated. This significantly reduces the time it takes to develop a model, allowing businesses to deploy their models faster. As a result, backend systems can be enhanced with machine learning capabilities in record time.
Example: Imagine you’re working on a recommendation system for an e-commerce website. Using AutoML, you can quickly build and deploy a model to personalize product recommendations for users without spending weeks training and fine-tuning the model.
- No Need for Deep Data Science Expertise
AutoML levels the playing field by allowing developers and business analysts—who may not have an extensive background in data science—to create machine learning models. This is particularly beneficial for small businesses or startups that may not have dedicated data science teams but still want to harness the power of machine learning.
Example: A developer at a small startup can use AutoML to build a model for dynamic pricing based on market trends and customer behavior. This means the developer can focus on integrating the model into the backend without needing advanced knowledge in machine learning algorithms.
- Improved Accuracy and Optimization
One of the most time-consuming aspects of machine learning is the process of tuning hyperparameters to optimize model performance. AutoML automates this process using techniques like grid search or random search, ensuring the best-performing model is selected for deployment. This results in more accurate models with optimized performance, reducing the risk of errors or mispredictions.
Example: For an anomaly detection system in a backend infrastructure, AutoML can test various models and automatically select the one that identifies suspicious activities with the highest accuracy. This saves time while ensuring the model performs well in real-world conditions.
- Reduced Cost and Resource Consumption
Traditional machine learning workflows can be resource-intensive, requiring significant computational power to train multiple models. AutoML systems automate this process, which often leads to more efficient use of resources. With AutoML, backend systems can run machine learning models on a smaller budget, making it accessible for companies of all sizes.
Example: A small online platform wants to predict user churn. Using AutoML, the platform can generate a churn prediction model without having to invest in expensive computational resources.
III. How AutoML Works
Now that we understand the benefits of AutoML, let’s break down how it works in backend development. AutoML automates several stages of the machine learning workflow, each of which we’ll cover below:
- Data Preprocessing
Raw data is often messy and incomplete, which can hinder the performance of machine learning models. AutoML takes care of data preprocessing by automatically handling missing values, normalizing data, and transforming features into the most useful format.
Example: If you’re building a model to predict sales, AutoML will automatically clean up your sales data by handling missing values and converting categorical variables (like product types) into numerical formats.
- Model Selection
Choosing the right algorithm for the problem at hand can be challenging, even for experienced data scientists. AutoML automatically selects the most appropriate machine learning algorithm based on the type of problem you’re trying to solve—whether it’s regression, classification, or clustering.
Example: For a fraud detection model, AutoML might select a classification algorithm like Random Forest or XGBoost, depending on the features of the data.
- Hyperparameter Tuning
Hyperparameters are critical in fine-tuning the performance of a machine learning model. AutoML handles hyperparameter tuning by testing various combinations of parameters to identify the optimal configuration. This saves time compared to manually adjusting parameters.
Example: In a model designed to predict customer purchasing behavior, AutoML will experiment with different hyperparameters to optimize the model’s performance and prediction accuracy.
- Model Evaluation
After the model is trained, it’s important to assess its performance using evaluation metrics like accuracy, precision, recall, or F1 score. AutoML automates this process, running several evaluation tests to determine which model works best.
Example: Once AutoML builds the model, it might automatically test it using a set of unseen data to ensure it performs well in real-world scenarios.
- Deployment
Once the best model is selected, AutoML assists with deploying the model into the backend system. Whether you’re using cloud services like AWS or Google Cloud, or on-premise infrastructure, AutoML provides tools for easy deployment.
Example: For an inventory management system, AutoML could help deploy a model that predicts stock levels and automatically updates the backend system with fresh predictions as new data comes in.
IV. Use Cases of AutoML in Backend Development
The versatility of AutoML makes it applicable to a wide range of use cases in backend development. Let’s look at some real-world examples:
- Customer Segmentation and Personalization
AutoML can help e-commerce platforms segment customers based on their behavior and preferences, allowing for better-targeted marketing and personalized recommendations. This can significantly improve user engagement and conversion rates.
- Predictive Maintenance
Backend systems in industries like manufacturing or transportation can leverage AutoML to predict when machines are likely to fail, allowing businesses to perform maintenance proactively and avoid costly downtime.
- Churn Prediction
For businesses relying on subscription models, AutoML can predict when customers are likely to cancel their subscriptions. By identifying these users early, businesses can take steps to retain them, such as offering discounts or personalized incentives.
V. Challenges and Considerations of AutoML in Backend Development
While AutoML brings many benefits, it’s important to consider the challenges it may introduce:
- Data Quality:
AutoML models rely heavily on data quality. If the input data is noisy, incomplete, or biased, the model’s performance could suffer.
- Complexity of Deployment:
While AutoML simplifies the process of model development, deploying models into production and integrating them with backend systems still requires a certain level of technical expertise.
- Overfitting Risk:
In some cases, AutoML models may overfit the training data, resulting in a model that performs well on the training set but poorly on new, unseen data.
In conclusion, AutoML is revolutionizing backend development by streamlining the machine learning model creation and deployment process. By making it easier, faster, and more efficient to deploy powerful ML models, AutoML opens the door for businesses of all sizes to leverage the benefits of machine learning, even without a dedicated data science team. With its ability to automate tedious tasks, AutoML enables developers to focus on creating innovative backend systems that improve user experiences, streamline operations, and drive growth.
h. Association Rule Learning for Database Optimization
 Association Rule Learning (ARL) is one of the most valuable techniques in machine learning, particularly when it comes to optimizing databases and enhancing backend systems. This technique helps to uncover hidden patterns and relationships between variables in large datasets, which can significantly improve the performance of database systems. ARL is a key part of the broader class of unsupervised learning algorithms and is most commonly used in fields like market basket analysis, recommendation systems, and customer behavior prediction.
Association Rule Learning (ARL) is one of the most valuable techniques in machine learning, particularly when it comes to optimizing databases and enhancing backend systems. This technique helps to uncover hidden patterns and relationships between variables in large datasets, which can significantly improve the performance of database systems. ARL is a key part of the broader class of unsupervised learning algorithms and is most commonly used in fields like market basket analysis, recommendation systems, and customer behavior prediction.
In backend development, the application of Association Rule Learning can make your database more efficient, helping to speed up query processing, optimize indexing, and improve data retrieval times. Let’s dive deep into what Association Rule Learning is, how it works, and how it can optimize your backend databases.
I. What is Association Rule Learning (ARL)?
Association Rule Learning is a machine learning technique used to discover interesting relationships (associations) between variables in large datasets. The most common application of ARL is market basket analysis, where businesses examine customer purchase patterns to understand which products are often bought together. However, its use extends far beyond this, and it can be applied to various other domains, including backend database optimization.
Association rules consist of two parts: an antecedent (the “if” part) and a consequent (the “then” part). A typical rule might look something like this:
If a customer buys bread and butter, they are likely to buy jam.
In this example, “bread and butter” is the antecedent, and “jam” is the consequent. In the context of databases, these relationships can be used to optimize indexing and improve data retrieval, making your backend system more efficient.
II. How Does Association Rule Learning Work?
Association Rule Learning typically follows a three-step process:
- Frequent Itemset Generation
The first step in Association Rule Learning is identifying frequent itemsets—sets of items that frequently occur together in transactions. This can be done using algorithms like the Apriori Algorithm or FP-Growth, which analyze the dataset to find associations between different items or variables.
Example: In an e-commerce database, you may find that customers who purchase smartphones are also likely to buy phone cases, screen protectors, or chargers. The combination of smartphones and these accessories forms a frequent itemset.
- Rule Generation
Once frequent itemsets are identified, the next step is to generate association rules from these itemsets. The rules are generated based on the frequency or probability of items appearing together in the dataset. The confidence of a rule represents how often the consequent (e.g., buying jam) happens when the antecedent (e.g., buying bread and butter) is true.
Example: From the frequent itemset of smartphones and accessories, you could generate a rule like:
If a customer buys a smartphone, they are likely to buy a phone case (confidence of 70%).
- Rule Evaluation
After generating the rules, it’s essential to evaluate them using metrics like support, confidence, and lift to ensure their validity and usefulness.
- Support refers to the frequency with which the rule occurs in the entire dataset.
- Confidence measures the likelihood that the rule holds true.
- Lift indicates the strength of the association by comparing the rule’s probability to the overall probability of the consequent.
Example: If the lift of a rule “If a customer buys a smartphone, they are likely to buy a phone case” is greater than 1, this suggests a strong association between smartphones and phone cases.
III. Benefits of Using ARL for Database Optimization
Association Rule Learning is not just about finding relationships in data—it also plays a pivotal role in optimizing backend systems. Here’s how ARL can enhance your database performance:
- Improved Query Optimization
One of the biggest challenges in backend development is ensuring fast and efficient query performance, especially when dealing with large datasets. ARL can identify frequent relationships between database attributes and suggest which columns or fields should be indexed to improve query response times. By optimizing indexing based on these associations, backend systems can return results more quickly, even with large amounts of data.
Example: Suppose you have a database storing information about user preferences. ARL could help identify which attributes (e.g., age, location, and purchase history) are most frequently queried together. By creating an index based on these attributes, queries that involve these fields can be executed faster.
- Data Compression and Storage Optimization
ARL can also be used to optimize data storage by identifying patterns and redundancies in the database. By leveraging association rules, you can reduce data redundancy, leading to more efficient storage and less disk space usage. This is particularly useful for large databases that need to store a massive amount of data without compromising on performance.
Example: If you find that certain data columns are often queried together, you can optimize the storage structure by grouping these columns or compressing them into a more efficient format.
- Enhanced Data Retrieval
Database retrieval times can be improved significantly by applying ARL to enhance search algorithms. By understanding the frequent relationships between data points, ARL can help backend systems retrieve relevant information faster. This makes systems more responsive and user-friendly.
Example: In a product catalog for an e-commerce website, ARL can help recommend related products based on a user’s previous searches or purchases. This means users don’t have to spend time searching for additional products; the system can proactively present them.
- Anomaly Detection
In some cases, ARL can be used to detect unusual patterns in the data that might indicate issues such as fraud or system malfunctions. By learning the typical associations between different variables, backend systems can flag any data that falls outside of these patterns, signaling potential errors or fraud attempts.
Example: If a database of financial transactions normally shows a strong correlation between certain types of purchases and locations, a sudden change in that pattern could trigger an alert for potential fraudulent activity.
IV. Real-World Use Cases of ARL in Backend Development
- E-Commerce and Retail
In the e-commerce industry, ARL is widely used for market basket analysis to identify product associations. This helps businesses design more effective product bundling strategies and optimize inventory management. By analyzing purchase history and identifying items frequently bought together, e-commerce platforms can deliver better recommendations to customers, increasing sales and customer satisfaction.
- Healthcare Systems
In healthcare, ARL can be used to analyze patient data and identify associations between symptoms, diagnoses, and treatments. This can help healthcare providers make more accurate decisions and optimize their backend systems for faster patient data retrieval.
- Banking and Fraud Detection
ARL can also help banks identify fraudulent activities by detecting unusual patterns in financial transactions. If certain transactions normally occur together but an anomaly arises (e.g., a user in one location trying to withdraw money in a different location), ARL can help flag this as a potential fraud case.
V. Challenges and Considerations for Using ARL in Backend Development
While ARL offers numerous benefits, it also comes with its own set of challenges:
- Data Privacy and Security
In industries like healthcare and banking, handling sensitive data with ARL can raise privacy concerns. Proper measures must be in place to ensure that the use of ARL doesn’t violate any regulations or expose sensitive information.
- Computational Complexity
The process of identifying frequent itemsets in large datasets can be computationally intensive, especially when dealing with high-dimensional data. Optimizing these algorithms for performance is crucial in backend systems.
- Overfitting Risk
Just like any machine learning model, ARL algorithms can suffer from overfitting if they are trained on limited data. It’s important to evaluate the results thoroughly and ensure that the rules generated are meaningful and not just artifacts of the training data.
Association Rule Learning is an essential technique for backend development, especially when optimizing large databases. By uncovering hidden relationships and patterns in data, ARL not only enhances database performance but also improves the efficiency of backend systems across industries. Whether it’s speeding up query times, reducing redundancy, or enhancing data retrieval, ARL is a powerful tool that can drive significant improvements in backend development.
i. Unsupervised Learning for Data Clustering
 In the fast-paced world of backend development, optimizing data handling and extraction processes is crucial. One powerful machine learning technique that can significantly enhance these processes is Unsupervised Learning, specifically through Data Clustering. Data clustering is a key application of unsupervised learning where the model tries to group data points that share common characteristics without any labeled data. This can make a massive difference in how databases are managed, data is retrieved, and backend systems scale to handle large volumes of information efficiently.
In the fast-paced world of backend development, optimizing data handling and extraction processes is crucial. One powerful machine learning technique that can significantly enhance these processes is Unsupervised Learning, specifically through Data Clustering. Data clustering is a key application of unsupervised learning where the model tries to group data points that share common characteristics without any labeled data. This can make a massive difference in how databases are managed, data is retrieved, and backend systems scale to handle large volumes of information efficiently.
Let’s dive into what unsupervised learning is, how clustering works, and how it can benefit your backend development by optimizing your database management and improving overall performance.
I. What is Unsupervised Learning?
Unsupervised learning is a category of machine learning that uses data that has not been labeled or categorized. Unlike supervised learning, where algorithms are trained using labeled data (meaning each data point has a corresponding outcome), unsupervised learning algorithms look for hidden structures in the data without prior knowledge of the correct answers.
One of the most common techniques in unsupervised learning is data clustering, where the goal is to group similar data points together. Clustering allows systems to identify patterns and structures within complex, unlabelled datasets. In backend development, this is especially valuable because it allows your system to automatically recognize groups, patterns, or trends without needing to manually specify them.
II. How Does Data Clustering Work?
Data clustering works by organizing a dataset into clusters—groups of data points that are similar to each other based on certain characteristics. The idea is that data within the same cluster will share common features, and data points from different clusters will be as dissimilar as possible.
The process typically follows these steps:
- Selecting the Right Algorithm
The first step in data clustering is selecting the appropriate clustering algorithm. There are several algorithms available, but the most commonly used are:
- K-Means Clustering: This is one of the simplest and most widely used clustering algorithms. It involves grouping data into ‘K’ predefined clusters by minimizing the variance within each cluster.
- Hierarchical Clustering: This method builds a tree-like structure (dendrogram) that shows the relationship between data points, and it’s useful when you don’t know the number of clusters in advance.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): This algorithm focuses on areas of high data density and is useful for identifying clusters of varying shapes and sizes.
- Assigning Data Points to Clusters
After selecting the algorithm, the next step is to assign data points to their respective clusters. For example, in K-Means clustering, data points are assigned to the nearest centroid (mean value) of a cluster, and then the centroids are recalculated based on the new points in the cluster.
- Optimizing the Clusters
Once data points are assigned to clusters, the algorithm iterates through several steps of refining the clusters to ensure the best grouping. The goal is to reduce the intra-cluster distance (distance between points within the same cluster) and increase the inter-cluster distance (distance between points in different clusters).
Example: Imagine a dataset containing thousands of customer records. A clustering algorithm can group customers based on similar attributes like purchase behavior, location, or browsing patterns.
III. Benefits of Using Data Clustering in Backend Development
Data clustering has several practical applications in backend development, particularly when it comes to optimizing database performance, automating data analysis, and improving system responsiveness.
- Improved Data Indexing and Retrieval
One of the primary benefits of clustering is that it can enhance data indexing. By grouping similar data together, the database can optimize how it stores and retrieves data. Instead of searching through large, unorganized datasets, the system can quickly target specific clusters, improving retrieval times and reducing computational overhead.
Example: Imagine a backend system for an e-commerce platform. By using clustering, the platform can group similar products (e.g., electronics, clothing, etc.). When a user searches for a product, the system can target the relevant clusters, providing faster and more accurate results.
- Personalized Recommendations
Clustering is a key component of recommendation engines, which are crucial for personalizing user experiences. For example, clustering can help group users with similar behavior patterns (e.g., browsing habits, purchase history) and recommend products or services that other users in the same cluster have enjoyed.
Example: A music streaming platform might cluster users based on their listening habits and recommend songs or playlists that are popular within the same cluster. This personalization enhances user engagement and satisfaction.
- Automated Data Segmentation
In many backend systems, data needs to be divided into different categories for analysis or processing. Data clustering allows the system to automatically segment data without human intervention. This is particularly useful in applications where manual segmentation is time-consuming or impractical.
Example: In a backend system for a healthcare application, clustering can help automatically categorize patients into groups based on their medical histories, allowing healthcare providers to analyze patterns in specific patient segments (e.g., chronic illness, recovery rates).
- Anomaly Detection
Data clustering can also help detect anomalies in the data. Since clusters are formed based on similarity, data points that don’t belong to any cluster or significantly differ from others will stand out. This can be useful for detecting outliers, errors, or unusual behaviors in the system.
Example: In a financial backend system, clustering can help identify fraudulent transactions by spotting outliers that do not fit into the usual patterns of behavior.
- Optimizing Backend Resources
In large-scale backend systems, managing computational resources efficiently is critical. Data clustering can help optimize resource allocation by grouping similar tasks together, ensuring that resources are allocated to the most relevant processes based on data trends and system load.
Example: In cloud computing, clustering can help allocate resources to servers handling similar types of data or user requests, ensuring that each server operates efficiently and without unnecessary strain.
IV. Real-World Applications of Data Clustering in Backend Development
- Customer Segmentation in E-Commerce
Online retailers use clustering to categorize customers based on purchase behavior, allowing businesses to offer targeted promotions or optimize inventory management. For instance, customers who frequently purchase tech gadgets might receive personalized discounts on the latest gadgets.
- Predictive Maintenance in Manufacturing
Data clustering is used in backend systems to monitor and predict equipment failures in manufacturing plants. By clustering machinery data, systems can identify patterns of wear and tear and schedule maintenance before breakdowns occur.
- Image Recognition and Organization
Backend systems involved in image processing, like those used in photo storage apps or security cameras, use clustering to group similar images together. This allows systems to organize images efficiently, making it easier to search for similar items or detect patterns.
V. Challenges and Considerations of Data Clustering
While clustering offers numerous benefits, there are some challenges to keep in mind:
- Choosing the Right Number of Clusters
A common problem with clustering is deciding how many clusters to use. Too few clusters may lead to overly broad categories, while too many clusters can lead to overfitting. Finding the right balance often requires experimenting with different algorithms and parameters.
- Dealing with Noisy Data
Clustering can be sensitive to noisy data—data that’s irrelevant or inconsistent. It’s essential to preprocess your data properly by filtering out noise to ensure that the clustering algorithm produces meaningful results.
- Scalability
Clustering algorithms can be computationally expensive, especially when working with large datasets. In backend systems, this can lead to slow processing times or system overloads. It’s important to choose algorithms that are optimized for large-scale data.
Incorporating unsupervised learning and data clustering into backend development not only optimizes data management but also drives more efficient systems. Whether it’s improving data retrieval, detecting anomalies, or personalizing recommendations, clustering brings significant advantages to the backend world. By automating data grouping and uncovering hidden patterns, backend developers can create faster, smarter, and more intuitive systems that scale effortlessly.
j. Supervised Learning for User Behavior Prediction
 In the world of backend development, one of the primary goals is to provide users with a seamless and personalized experience. A great way to achieve this is through Supervised Learning—a machine learning technique that uses labeled data to make predictions about future behavior. By utilizing Supervised Learning for User Behavior Prediction, backend systems can anticipate user actions, optimize services, and create a more dynamic, engaging experience.
In the world of backend development, one of the primary goals is to provide users with a seamless and personalized experience. A great way to achieve this is through Supervised Learning—a machine learning technique that uses labeled data to make predictions about future behavior. By utilizing Supervised Learning for User Behavior Prediction, backend systems can anticipate user actions, optimize services, and create a more dynamic, engaging experience.
User behavior prediction is a powerful tool in many modern backend systems. It can forecast what a user might do next based on past behavior, helping systems suggest personalized content, optimize search results, and even predict future purchases or actions. In this section, we’ll explore how supervised learning works, how it’s applied in backend development, and the benefits it offers for businesses and users alike.
I. What is Supervised Learning?
Supervised learning is a type of machine learning where the algorithm is trained using labeled data. This means that the training dataset includes both the input data (features) and the correct output (labels). The goal is for the algorithm to learn the relationship between the input and output so it can predict the output for new, unseen data.
In user behavior prediction, the input data might include things like user demographics, past activities, and interaction patterns, while the output would be a prediction of what the user is likely to do next.
Supervised learning is powerful because it relies on historical data to make predictions, meaning it can be highly accurate when used correctly. The key difference between supervised learning and unsupervised learning is that supervised learning requires labeled data, which helps guide the algorithm in finding patterns.
II. How Does Supervised Learning Work for User Behavior Prediction?
The process of applying supervised learning to user behavior prediction follows a few key steps:
- Collecting Labeled Data
The first step is to gather data that includes both the features (inputs) and the labels (outputs). For example, in an e-commerce site, the features might include a user’s past purchases, browsing history, time spent on the site, and location, while the label might be whether the user made a purchase after a certain event or action (like viewing a product page).
Example: If a user clicks on a product, the system might track their actions (viewing similar items, adding to cart, etc.) and label whether or not they completed the purchase. This labeled data becomes the foundation for training the model.
- Choosing the Right Algorithm
Once labeled data is collected, the next step is to select a supervised learning algorithm. Common algorithms for user behavior prediction include:
- Logistic Regression: Often used for binary predictions (e.g., will the user click or not click?).
- Decision Trees: These break down data into a tree-like structure, making decisions based on feature values. It’s great for identifying patterns and relationships in user behavior.
- Random Forests: This is an ensemble learning technique that combines multiple decision trees to improve accuracy.
- Support Vector Machines (SVM): SVM is effective in high-dimensional spaces and is good for making predictions based on complex data.
- Training the Model
After choosing the algorithm, the next step is to train the model. This involves feeding the labeled data into the algorithm so it can learn the patterns between inputs and outputs. The algorithm will adjust its internal parameters to minimize errors and increase prediction accuracy.
- Making Predictions
Once the model is trained, it can be used to make predictions. For user behavior prediction, this might mean predicting whether a user will purchase a product, click on a specific ad, or abandon a shopping cart.
Example: After analyzing user behavior, the system might predict that a user who has browsed three similar products is likely to buy one of them within the next 24 hours.
- Evaluating and Refining the Model
The final step is to evaluate the performance of the model using metrics like accuracy, precision, recall, and F1 score. If the model’s predictions aren’t accurate enough, developers can refine it by tuning the hyperparameters or adding more labeled data for training.
III. Real-World Applications of Supervised Learning in Backend Development
Supervised learning is incredibly versatile and can be used in a wide range of applications to enhance backend systems. Here are a few common examples where user behavior prediction shines:
- Personalized Recommendations
One of the most popular uses of supervised learning for predicting user behavior is recommendation systems. These systems analyze a user’s past behavior and predict what products, services, or content they might be interested in next. Platforms like Netflix, Amazon, and Spotify all use supervised learning to suggest new movies, products, or music based on user preferences.
Example: In an e-commerce store, a backend system might use supervised learning to predict which products a user will be most likely to purchase based on their browsing and shopping history. The system will tailor the suggestions to match the individual’s preferences, increasing the chances of conversion.
- Dynamic Pricing Models
Supervised learning can also help optimize pricing by predicting user demand based on behavior patterns. For example, airlines use supervised learning to adjust ticket prices dynamically. By analyzing past behavior, like booking patterns and flight searches, the system can predict the likelihood of a customer purchasing at a specific price point.
Example: A backend system for an airline might predict that a user is likely to book a flight within a specific price range based on their past search behavior, allowing the system to adjust prices accordingly.
- Fraud Detection
Backend systems can use supervised learning to predict whether a transaction is legitimate or fraudulent based on user behavior. By training a model on past data of fraudulent and non-fraudulent transactions, the system can identify unusual patterns that might suggest fraudulent activity.
Example: A bank might use supervised learning to analyze user spending behavior and detect anomalies such as large, unexpected withdrawals or purchases from unusual locations.
- Customer Churn Prediction
In subscription-based services, predicting which users are likely to cancel their subscriptions (i.e., churn) is essential for retaining customers. Supervised learning models can analyze user behavior, such as login frequency, usage patterns, and support requests, to predict churn and allow businesses to take preemptive action.
Example: A streaming service might predict that a user is likely to cancel their subscription based on declining engagement, allowing the company to offer discounts or special offers to retain the customer.
- Sentiment Analysis
Supervised learning can also be applied to sentiment analysis to predict how a user feels about a product or service based on their reviews, social media posts, or feedback. This can help businesses fine-tune their backend systems to meet customer needs.
Example: A backend system might analyze customer reviews of a product and predict whether the general sentiment is positive or negative, allowing businesses to address issues quickly.
IV. Challenges and Considerations in User Behavior Prediction
While supervised learning for user behavior prediction offers significant benefits, there are some challenges to be aware of:
- Data Privacy and Ethics
Collecting user data for predictive analysis raises concerns about privacy. It’s essential to ensure that data is collected ethically and that user consent is obtained. Additionally, developers must ensure that sensitive information is handled securely and that predictions are made in a way that respects user privacy.
- Data Quality and Bias
The accuracy of predictions heavily depends on the quality of the labeled data. If the data is incomplete, inconsistent, or biased, the model will produce poor predictions. It’s important to clean and preprocess data before training the model to ensure reliable results.
- Overfitting and Underfitting
Overfitting occurs when the model is too complex and fits the training data too well, leading to poor generalization to new data. On the other hand, underfitting occurs when the model is too simple to capture the underlying patterns in the data. Balancing the complexity of the model is crucial for accurate predictions.
By leveraging supervised learning for user behavior prediction, backend developers can significantly enhance the user experience, increase engagement, and optimize business outcomes. Whether it’s recommending products, predicting churn, or detecting fraud, predicting user behavior with high accuracy helps backend systems become more intelligent, efficient, and customer-centric.
k. Transfer Learning for Efficient Model Training
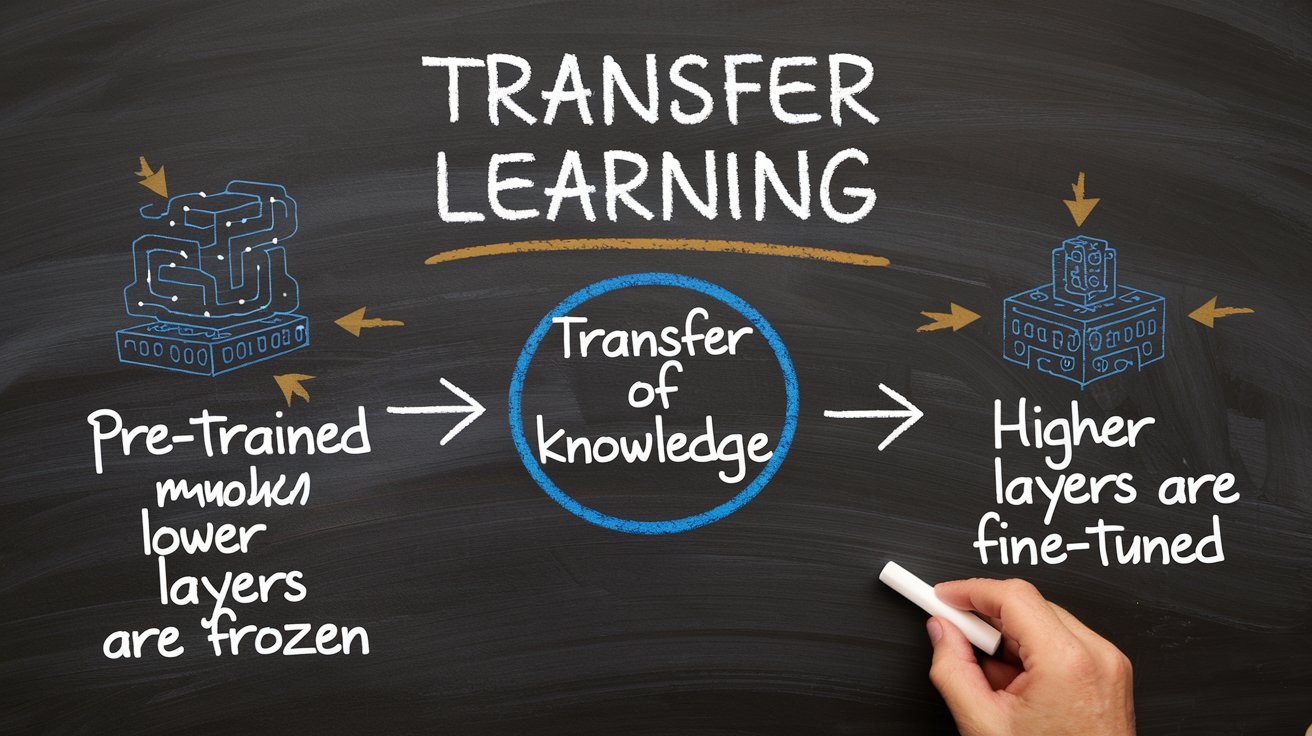 In the rapidly evolving world of backend development, creating machine learning models can be time-consuming and resource-intensive. Traditionally, training models from scratch requires vast amounts of data and computational power. But what if you could leverage existing knowledge to speed up the process? That’s where Transfer Learning comes into play.
In the rapidly evolving world of backend development, creating machine learning models can be time-consuming and resource-intensive. Traditionally, training models from scratch requires vast amounts of data and computational power. But what if you could leverage existing knowledge to speed up the process? That’s where Transfer Learning comes into play.
Transfer Learning is a powerful machine learning technique that allows developers to use pre-trained models and adapt them to new, related tasks. This approach has revolutionized how backend systems are developed, making it easier and faster to deploy machine learning models without the need for large amounts of data or massive computing resources.
In this section, we’ll explore what transfer learning is, how it works, and how it’s being used to make backend development more efficient. We’ll also take a look at practical examples, benefits, and some fun facts to keep things engaging!
I. What is Transfer Learning?
Transfer learning is a method in machine learning where a model developed for one task is reused and adapted to a different but related task. Instead of starting from scratch, developers use the knowledge gained from the first task to help train the model for a new one. This concept mimics how humans learn: we often apply knowledge from past experiences to understand new situations.
In traditional machine learning, you train a model on a specific dataset for a specific task. However, this approach requires a lot of labeled data and computational power. With transfer learning, you take a model that has already been trained on a large dataset for a task and “fine-tune” it on a smaller dataset for a new task. This process allows you to take advantage of the general knowledge learned by the model, which can drastically reduce the amount of data and time needed for training.
Think of it as borrowing a car from your friend to drive in a new city. You don’t need to learn how to drive the car from scratch; you simply use what you know and adapt it to the new situation!
II. How Does Transfer Learning Work?
Transfer learning typically works in a few distinct steps. Here’s how it generally goes:
- Pre-trained Model Selection
The first step in transfer learning is to select an appropriate pre-trained model. For example, if you’re building a backend system that involves image recognition, you might use a model that has already been trained on millions of images (like ResNet or VGG). These models have learned to identify patterns, shapes, and features from the training data.
- Freezing Layers
Once the pre-trained model is selected, you can freeze the lower layers of the model. The lower layers are responsible for learning general features like edges, textures, and colors, which are common to many tasks. These layers don’t need to be retrained since they’ve already learned useful patterns.
- Fine-tuning Higher Layers
The higher layers of the model are responsible for task-specific features. These are the parts of the model that make predictions about the specific task at hand. In transfer learning, you fine-tune these layers to adjust the model’s behavior for your particular task. For instance, if you’re using an image recognition model to identify cats and dogs, you might adjust the top layers to distinguish between different breeds of dogs.
- Training on New Data
Finally, you can train the model on your new, smaller dataset to make it better suited to your task. Since the model already has a solid foundation (learned from the pre-trained model), this step requires much less data and time compared to training a model from scratch.
- Making Predictions
Once fine-tuning is complete, the model is ready to make predictions based on the new data. It uses the knowledge from the original task (the “transfer”) and adapts it to the new task.
III. Real-World Applications of Transfer Learning in Backend Development
Transfer learning is being applied across various industries to make backend systems more efficient. Let’s look at a few examples:
- Image Recognition in E-commerce
E-commerce platforms often use image recognition to categorize products, detect defects, or enhance search functionality. By using a pre-trained model that has already learned to recognize various objects, companies can quickly adapt it to classify specific products in their catalog.
Example: A fashion e-commerce site might use a pre-trained model to recognize general features like clothes, shoes, or accessories. They can then fine-tune it to recognize specific types of dresses, shoes, or jewelry that are unique to their catalog.
- Natural Language Processing (NLP) for Chatbots
NLP is a field of machine learning focused on understanding and generating human language. Pre-trained models like BERT and GPT have been trained on massive amounts of text data. These models can be used for a variety of NLP tasks, such as sentiment analysis, language translation, and chatbot functionality.
Example: A backend system for a customer service chatbot might use a pre-trained NLP model and fine-tune it to understand and respond to specific customer queries, reducing the amount of data and time required for training.
- Speech Recognition for Virtual Assistants
Virtual assistants like Siri, Alexa, and Google Assistant rely heavily on speech recognition to interpret user commands. Transfer learning enables the backend systems of these assistants to understand different accents, languages, and phrases, all while using a pre-trained model for faster adaptation.
Example: A voice assistant might use a pre-trained speech recognition model and fine-tune it to recognize specific commands in a different language or dialect. This approach allows the assistant to become more adaptable and accurate without having to start training from scratch.
- Predictive Analytics for Healthcare
In healthcare, transfer learning can be used to predict patient outcomes based on medical records and images. Models trained on general medical data can be adapted to predict specific diseases or conditions.
Example: A pre-trained model trained on a large dataset of medical imaging can be adapted to predict whether a new scan indicates the presence of a specific disease, like lung cancer, by fine-tuning it with data specific to that condition.
IV. Benefits of Transfer Learning
Transfer learning has several benefits that make it a popular choice for backend development:
- Reduced Training Time
One of the most significant advantages of transfer learning is that it drastically reduces the time required to train models. Since the pre-trained model has already learned many general features, fine-tuning it with your data takes far less time than starting from scratch.
- Smaller Datasets
Training machine learning models from scratch typically requires vast amounts of labeled data. However, with transfer learning, you can work with smaller datasets because the pre-trained model already understands general patterns.
- Lower Computational Cost
Training a model from scratch can be computationally expensive, especially when using deep learning techniques. Transfer learning allows you to avoid the heavy computational burden associated with training from the ground up.
- Improved Accuracy
Because transfer learning leverages knowledge from large datasets, the resulting model often performs better, especially when there’s a lack of sufficient data for the new task. Fine-tuning helps the model adjust and improve its performance for the specific problem.
Fun Fact : Did you know? The concept of transfer learning is not new! It’s been around for decades, but its popularity soared with the rise of deep learning and massive computing power. Transfer learning is essentially “knowledge sharing” between models. So, in a way, models are helping each other out, much like how we borrow ideas from our friends to solve problems!
Conclusion
Transfer learning has become a game-changer in machine learning, particularly in backend development. By using pre-trained models and adapting them to new tasks, developers can save time, reduce computational costs, and improve the accuracy of their models. It’s a win-win! Whether it’s for image recognition, natural language processing, or predictive analytics, transfer learning enables backend systems to become more efficient and capable without reinventing the wheel every time.
So, if you’re looking to speed up your machine learning models and make them more powerful, don’t forget to leverage the power of transfer learning!
l. Neural Architecture Search (NAS) for Model Optimization
 In the fast-paced world of backend development, model optimization is crucial for making machine learning systems efficient, faster, and more accurate. If you’ve ever tried to develop a machine learning model from scratch, you probably know how overwhelming it can be to choose the right architecture. Do you go with a deep neural network (DNN), convolutional neural network (CNN), or recurrent neural network (RNN)? And once you decide on the architecture, how do you fine-tune the model’s hyperparameters to achieve the best performance? This is where Neural Architecture Search (NAS) comes in to save the day!
In the fast-paced world of backend development, model optimization is crucial for making machine learning systems efficient, faster, and more accurate. If you’ve ever tried to develop a machine learning model from scratch, you probably know how overwhelming it can be to choose the right architecture. Do you go with a deep neural network (DNN), convolutional neural network (CNN), or recurrent neural network (RNN)? And once you decide on the architecture, how do you fine-tune the model’s hyperparameters to achieve the best performance? This is where Neural Architecture Search (NAS) comes in to save the day!
NAS is an innovative technique in machine learning that automates the process of designing neural networks by finding the best architecture for a given problem. It removes the guesswork and human trial-and-error that usually goes into selecting and tuning a model architecture, making it more efficient and scalable. In this section, we’ll explore what NAS is, how it works, and how it’s transforming backend development, especially in optimizing models for better performance.
I. What is Neural Architecture Search (NAS)?
At its core, Neural Architecture Search (NAS) is a method of automating the design of neural networks. Traditionally, selecting the right architecture for a machine learning model is a painstaking and time-consuming process that requires a deep understanding of the problem at hand. Researchers and developers often experiment with different architectures and hyperparameters to find the combination that works best.
However, NAS automates this process by using search algorithms to explore different architectures and identify the most efficient one for a specific task. The goal of NAS is to discover the optimal architecture that minimizes computational cost while maximizing model accuracy. Essentially, NAS acts as a “robot” that finds the best neural network structure for you, saving time, effort, and resources.
Think of NAS as a personal architect for your machine learning model. Instead of you manually designing a building (or model), NAS looks at different blueprints and figures out which one will be the most efficient for your needs.
II. How Does NAS Work?
NAS is typically implemented using one of the following search strategies:
- Reinforcement Learning-Based Search
One of the most popular approaches for NAS is using reinforcement learning (RL). In this method, an RL agent is trained to search for the optimal neural network architecture. The agent takes actions, such as choosing which layer types or parameters to use, and receives feedback (rewards or penalties) based on the performance of the architecture.
- Example: The agent might try out different combinations of layers, such as adding a convolutional layer followed by a pooling layer. It evaluates the performance of each combination, receiving a reward if the model performs well and a penalty if it doesn’t.
- Evolutionary Algorithms
Another popular method for NAS involves using evolutionary algorithms (EA). In this approach, a population of neural network architectures is evolved over several generations. Each “individual” in the population represents a neural network architecture, and the algorithm evolves these individuals by selecting the best ones, combining them, and introducing mutations to create new architectures.
- Example: The algorithm might start with a random population of architectures, selecting the ones that perform best and then mixing and mutating them to create new architectures. This process continues until the best architecture emerges.
- Gradient-Based Search
This search strategy uses gradient descent techniques to directly optimize the architecture of the neural network. It works by modifying the architecture based on the gradients of the loss function, allowing the model to gradually improve its structure.
- Example: Using gradient-based NAS, the algorithm could tweak the architecture’s parameters (such as layer sizes or types) and directly adjust them based on the loss function’s gradients.
III. Applications of NAS in Backend Development
Now that we understand the basics of NAS, let’s explore how it’s applied in backend development to optimize machine learning models and make systems more efficient.
- Automating Model Architecture Design
One of the primary benefits of NAS is that it automates the process of designing neural networks. This is especially helpful in backend development, where there are often many different architectures to choose from, each with its own advantages and trade-offs. With NAS, developers can save time and resources by allowing the system to search for the best architecture on its own.
Example: A backend developer building a recommendation system can use NAS to automatically search for the optimal architecture that maximizes accuracy while minimizing computational resources, making the system more efficient.
- Optimizing Hyperparameters
NAS can also be used to optimize hyperparameters such as learning rates, batch sizes, and the number of layers in a neural network. These hyperparameters can have a significant impact on the performance of a machine learning model, and NAS can help find the optimal combination for a given problem.
Example: If you’re training a deep learning model for image classification, NAS can help optimize the number of layers, layer types, and kernel sizes to ensure the model performs at its best with minimal computational cost.
- Improving Model Accuracy and Efficiency
With the ability to explore a vast range of architectural configurations, NAS can help improve the accuracy of machine learning models while also making them more efficient in terms of speed and memory usage. This is crucial in backend development, where resource constraints are often a factor.
Example: In real-time systems like fraud detection or recommendation engines, backend developers can use NAS to optimize the model for both fast decision-making and high accuracy, ensuring that the system operates efficiently without sacrificing performance.
- Personalized Solutions for Specific Use Cases
Every machine learning problem is unique, and the optimal architecture for one problem may not be suitable for another. NAS allows developers to create customized models for specific use cases, tailoring the architecture to meet the needs of the problem at hand.
Example: A backend developer working on a healthcare application can use NAS to design a model architecture that is tailored to the specific task of predicting patient outcomes, optimizing the architecture based on the dataset and task requirements.
IV. Benefits of Using NAS in Backend Development
- Faster Model Optimization
By automating the process of searching for the best architecture, NAS significantly reduces the time required to optimize machine learning models. This can be especially valuable in backend development, where quick iteration is often essential to meet business needs.
- Resource Efficiency
NAS helps ensure that models are not only accurate but also efficient in terms of computational resources. This means that backend systems can handle large-scale operations without overloading servers or wasting processing power.
- Better Performance
Since NAS searches for the most optimal architecture for a given task, it often leads to improved performance compared to manually-designed models. Developers can achieve higher accuracy and faster processing times, which is crucial in modern backend systems.
- Scalability
With NAS, backend developers can easily scale their machine learning models as the needs of the business grow. Whether you’re working on a small-scale project or a massive enterprise system, NAS allows you to continuously improve the architecture to meet new demands.
Fun Fact : Did you know? The concept of automating the design of neural networks dates back to the 1980s, but it wasn’t until the 2010s that deep learning breakthroughs and massive computing power made Neural Architecture Search truly feasible. It’s like having a robot architect at your disposal to design the perfect building for you!
Conclusion
Neural Architecture Search (NAS) has revolutionized the way machine learning models are designed and optimized, especially in backend development. By automating the search for the best architecture and optimizing hyperparameters, NAS saves time, resources, and effort. With its ability to improve accuracy, efficiency, and scalability, NAS is becoming an essential tool for developers looking to create high-performance models for complex backend systems.
So, the next time you’re working on a backend project and find yourself stuck choosing the right architecture, remember that NAS could be your best friend in helping you find the optimal solution quickly and efficiently.
m. Meta-Learning for Adaptive System Performance
 Machine learning is powerful, but it can sometimes struggle to adapt to new tasks or environments. This is where Meta-Learning comes into play. Often referred to as “learning to learn,” meta-learning is a technique in machine learning that enables models to adapt quickly to new tasks with minimal data. When applied to backend development, meta-learning offers a remarkable way to create more efficient, adaptive systems that can respond intelligently to new challenges without needing to be retrained from scratch.
Machine learning is powerful, but it can sometimes struggle to adapt to new tasks or environments. This is where Meta-Learning comes into play. Often referred to as “learning to learn,” meta-learning is a technique in machine learning that enables models to adapt quickly to new tasks with minimal data. When applied to backend development, meta-learning offers a remarkable way to create more efficient, adaptive systems that can respond intelligently to new challenges without needing to be retrained from scratch.
In this section, we will dive into the concept of meta-learning, explore how it can improve system performance, and discuss why it’s one of the most innovative techniques for backend development today.
I. What is Meta-Learning?
Meta-learning, in its simplest form, is the process of training a model on a variety of tasks so that it can learn how to quickly adapt to new, unseen tasks. Instead of training a model from scratch every time it encounters a new problem, meta-learning enables the model to apply knowledge gained from previous tasks to solve new ones efficiently. It’s a bit like how you, as a human, can learn a new game faster once you’ve already mastered a few others. The core idea is that learning how to learn can drastically improve a system’s ability to generalize and adapt to new situations.
Meta-learning involves multiple levels of learning:
- Base Learner: This is the standard machine learning model that performs the task at hand (e.g., classification, regression).
- Meta-Learner: The meta-learner’s job is to learn the strategies that make the base learner more effective at new tasks. It’s the “higher-level” model that oversees the learning process.
Think of meta-learning as a teacher guiding a student through the learning process, showing them how to pick up new concepts with ease.
II. How Does Meta-Learning Work?
In meta-learning, the key idea is to train a model that can adapt quickly to new tasks by leveraging prior knowledge. To make this happen, meta-learning techniques generally fall into three categories:
- Model-Based Meta-Learning
In model-based meta-learning, the model itself is designed to be adaptable. It uses an internal memory structure or recurrent neural networks (RNNs) to store previous experiences and apply this stored knowledge to new tasks.
- Example: Imagine a chatbot that learns from every conversation it has. Instead of needing to be retrained every time it faces a new user query, the model can apply the insights it’s gathered from prior interactions to answer new questions more effectively.
- Optimization-Based Meta-Learning
This method focuses on optimizing the training process itself. Instead of training a model from scratch for every new task, optimization-based meta-learning algorithms adjust the learning rate or other hyperparameters based on previous experiences. These adjustments help the model learn faster when exposed to new data or environments.
- Example: A recommendation system might use meta-learning to adjust its hyperparameters so it can quickly adapt to a new user’s preferences without needing to retrain the entire system.
- Metric-Based Meta-Learning
In metric-based meta-learning, the focus is on creating a distance metric or similarity function that allows the model to compare new tasks to previously seen ones. By finding similarities between tasks, the model can make predictions about the new task by leveraging information from similar tasks.
- Example: For an image classification system, the model could learn to classify images of new animals by comparing them to previously seen animals and recognizing similarities in their features.
III. Applications of Meta-Learning in Backend Development
Meta-learning’s ability to improve adaptability makes it an excellent choice for backend systems that need to deal with dynamic, ever-changing environments. Below, we explore some of the ways meta-learning is transforming backend development:
- Dynamic Resource Allocation
Backend systems often need to dynamically allocate resources like memory, CPU, and bandwidth based on fluctuating workloads. Meta-learning can optimize this process by enabling systems to adapt to new workloads efficiently.
Example: In cloud computing, meta-learning algorithms can adjust resource allocation strategies as server demands change, ensuring that the system remains optimized without constant manual intervention.
- Personalized Content Delivery
Backend systems in content delivery networks (CDNs) or recommendation engines can benefit from meta-learning by adapting to new user preferences with minimal data. Rather than requiring retraining on every new user, the system can leverage knowledge from past users to recommend content that best fits new users.
Example: Streaming platforms like Netflix can use meta-learning to quickly adapt their recommendation algorithms to new subscribers, ensuring they get personalized suggestions right from the start.
- Adaptation to New Data
In backend systems that handle large datasets, the ability to quickly adapt to new data is vital. Meta-learning enables systems to continuously improve by learning from new data sources without requiring a complete overhaul.
Example: A fraud detection system that receives new types of fraudulent behavior data can use meta-learning to quickly adapt its models, helping to detect emerging fraud patterns without the need for exhaustive retraining.
- Improved Autonomous Systems
Meta-learning is also a game-changer for backend systems that rely on autonomous decision-making, such as in robotics or self-driving cars. These systems must be able to adapt to new situations in real-time, and meta-learning can help them learn faster in new environments.
Example: A self-driving car backend system might use meta-learning to improve its decision-making when driving in new, unfamiliar areas, applying its knowledge from similar past experiences to adapt to its surroundings.
IV. Benefits of Meta-Learning for Backend Systems
- Faster Adaptation to New Tasks
Meta-learning allows backend systems to adapt quickly to new tasks and environments with minimal retraining, making them more agile and efficient in responding to dynamic conditions.
- Reduced Data Requirements
Meta-learning reduces the amount of data needed to learn new tasks. This is especially useful in situations where data collection is expensive or time-consuming.
- Improved Generalization
By learning from a variety of tasks, meta-learning enables systems to generalize better to unseen problems. This means the backend system can handle a wider range of tasks without compromising performance.
- Resource Efficiency
With meta-learning, backend systems can optimize their learning and decision-making processes without overusing computational resources. This ensures that systems remain efficient even as the complexity of the tasks increases.
Thought-Provoking Fact : Did you know? While human learning often involves trial and error, meta-learning is inspired by the idea that humans can apply previous knowledge to new tasks. By training machine learning systems to mimic this human ability, we open the door to creating highly adaptable AI systems that can handle a wide variety of situations.
Conclusion
Meta-learning is an exciting frontier in machine learning, offering a way to create more adaptive, efficient, and intelligent backend systems. By enabling systems to learn how to learn, meta-learning reduces the need for retraining models from scratch, saving both time and computational resources. With applications ranging from resource allocation to personalized content delivery, it’s clear that meta-learning is a game-changer for backend development.
So, the next time you’re developing a backend system that needs to quickly adapt to new tasks or data, remember that meta-learning might just be the perfect solution for creating smarter, more flexible systems.
n. Federated Learning for Distributed Data Processing
 As we move into an era of smarter, more connected devices, the amount of data we generate is exploding. From mobile phones to IoT devices, every piece of technology is gathering information. However, traditional machine learning often requires that all the data be collected in one central location, which can pose problems in terms of privacy, efficiency, and scalability. This is where Federated Learning steps in as a game-changing solution.
As we move into an era of smarter, more connected devices, the amount of data we generate is exploding. From mobile phones to IoT devices, every piece of technology is gathering information. However, traditional machine learning often requires that all the data be collected in one central location, which can pose problems in terms of privacy, efficiency, and scalability. This is where Federated Learning steps in as a game-changing solution.
In this section, we’ll explore Federated Learning, its role in backend development, and how it revolutionizes the way we handle data by processing it across multiple devices rather than in one centralized server.
I. What is Federated Learning?
Federated learning is a decentralized machine learning technique that enables multiple devices or servers to collaboratively learn a model without sharing their data. In a traditional machine learning setup, the data is sent to a central server, where a model is trained and then returned to the devices. With federated learning, the training occurs locally on the device, and only the model updates are sent back to a central server, not the data itself.
This allows for machine learning models to be trained across multiple devices while keeping the data local and private. Federated learning is particularly useful for applications where data privacy is crucial, such as in healthcare, finance, and personal devices like smartphones.
II. How Does Federated Learning Work?
Federated learning involves three key stages:
- Initialization
The central server begins by sending the initial model to all participating devices. These devices are often distributed across a wide geographical area, and they could be smartphones, edge devices, or even IoT devices.
- Local Model Training
Each device uses its local data to train the model. This is where federated learning differs from traditional methods—each device performs computations on its data independently, so the data never leaves the device. The model might be trained for a specific task, such as object detection, speech recognition, or recommendation.
- Model Aggregation
After training, each device sends the updates (i.e., the learned parameters) back to the central server. The server aggregates these updates to form a new global model, which is then sent back to all devices for further training. This cycle continues until the model is optimized and performs well across all devices.
The beauty of federated learning is that it allows for continuous model improvement across devices without compromising data privacy or centralizing the data itself.
III. Advantages of Federated Learning
- Enhanced Privacy
Since federated learning trains models locally on devices, there is no need to send sensitive data to a central server. This dramatically enhances privacy and security, which is especially important in industries like healthcare, where personal information must be safeguarded.
Example: A fitness tracking app could use federated learning to improve its recommendations without ever collecting your personal health data. Instead, the data stays on your device, and only model updates are shared.
- Reduced Data Movement
Traditional machine learning involves the movement of large datasets to central servers, which can be slow and inefficient, particularly when the data is distributed across many devices. Federated learning minimizes data movement, reducing latency and network traffic.
- Scalability
Federated learning is inherently scalable because it leverages the computing power of a distributed network of devices. Whether it’s thousands of smartphones or IoT devices, federated learning can scale to accommodate massive datasets without overwhelming a single server.
- Efficiency and Real-time Learning
As devices continuously learn and update models locally, federated learning enables real-time improvements. Devices can adapt to new information quickly, providing users with more up-to-date predictions and recommendations without waiting for server-side updates.
IV. Applications of Federated Learning in Backend Development
Federated learning has found a range of applications in backend development, particularly in environments where data is distributed and privacy is important. Here are some examples:
- Smartphones and Personal Devices
One of the most common applications of federated learning is in smartphones. For example, Google’s Gboard keyboard app uses federated learning to improve predictive text and autocorrect features based on users’ typing habits. Instead of sending data back to the server, the device learns locally and shares only updates, enhancing privacy.
Example: With federated learning, the next time you type a message on your smartphone, your phone could adapt its predictions to your typing style, all without ever sending your private conversations to Google.
- Healthcare and Medical Data
In healthcare, federated learning enables hospitals and medical institutions to collaboratively train models on patient data without violating privacy laws like HIPAA. Medical institutions can work together to create predictive models for disease diagnosis without ever sharing patient data directly.
Example: Federated learning can be used to train a model that predicts the likelihood of a patient developing diabetes, based on their local health records. Each hospital trains its local model, and only the updates are shared, keeping the patient’s health data private.
- Financial Services
In the finance industry, federated learning can be used to detect fraud, assess credit risk, or recommend financial products, all while keeping customer data secure and private. Banks can collaborate to improve their models without ever sharing sensitive financial data.
Example: If several banks use federated learning to detect fraud, each bank could train its model locally on customer transaction data, and share only updates with a central server to enhance fraud detection across the entire banking network.
- Autonomous Vehicles
Autonomous vehicles (AVs) require massive amounts of data to train their systems for real-time decision-making. Federated learning allows AVs to improve their models without sending all the data to central servers. Instead, vehicles can train their models locally and share updates to improve safety across all vehicles.
Example: A fleet of self-driving cars could use federated learning to improve their navigation systems, learn from each other’s experiences on the road, and adapt to new environments without compromising user privacy.
V. Challenges of Federated Learning
While federated learning offers impressive advantages, it’s not without its challenges:
- Data Heterogeneity
Since each device may have different data types, qualities, and distributions, aggregating the model updates can be challenging. A model trained with data from one device might not generalize well to data from another, especially if the devices are highly heterogeneous (e.g., smartphones with different specifications).
- Communication Overhead
Although federated learning reduces the need for data movement, transmitting model updates still requires bandwidth. The communication cost of sending updates between devices and the central server can become significant, especially when large models are involved.
- Security and Privacy Risks
While federated learning enhances privacy by keeping data local, model updates themselves can potentially leak information. Attackers could exploit this information, leading to model inversion or data poisoning attacks.
Conclusion
Federated learning is rapidly becoming a key player in the world of machine learning, especially for backend development. By enabling decentralized training on distributed devices, it addresses critical concerns around data privacy, scalability, and efficiency. Whether it’s improving app features on smartphones or creating collaborative medical diagnostic systems, federated learning is enabling smarter, more secure systems that learn and improve without compromising privacy.
So, the next time you’re thinking about backend systems that need to scale while keeping data secure, remember that federated learning might just be the future of how we handle distributed data.
o. Explainable AI (XAI) for Model Transparency
 Machine learning models are incredibly powerful, often providing insights and predictions that would be difficult for humans to generate on their own. However, one major drawback of these models is that they tend to be “black boxes” — it’s hard to understand how they make decisions. This is especially concerning when these models are used in critical fields like healthcare, finance, or criminal justice, where knowing the reasoning behind a decision is just as important as the decision itself. That’s where Explainable AI (XAI) comes into play.
Machine learning models are incredibly powerful, often providing insights and predictions that would be difficult for humans to generate on their own. However, one major drawback of these models is that they tend to be “black boxes” — it’s hard to understand how they make decisions. This is especially concerning when these models are used in critical fields like healthcare, finance, or criminal justice, where knowing the reasoning behind a decision is just as important as the decision itself. That’s where Explainable AI (XAI) comes into play.
In this section, we’ll dive into what XAI is, why it’s important, and how it is transforming backend development, making machine learning more transparent, interpretable, and trustworthy.
I. What is Explainable AI (XAI)?
Explainable AI (XAI) refers to a set of techniques and methods that make the decisions of AI models more transparent and understandable to humans. The goal of XAI is to allow users to comprehend and trust the decisions made by machine learning systems, especially in high-stakes situations.
While traditional machine learning models, like deep neural networks, often deliver excellent results, their “black box” nature makes them difficult to explain. For example, a deep learning model might predict that a patient has a high risk of heart disease, but it doesn’t provide an easy explanation of why it made that prediction.
XAI seeks to address this problem by providing clear, human-readable explanations of model behavior, helping to bridge the gap between the complexity of the model and the need for accountability and trust.
II. Why is Explainable AI Important?
- Building Trust
One of the key reasons for using explainable AI is to build trust in AI systems. If a machine learning model is making decisions that directly affect people’s lives (like loan approvals or medical diagnoses), users need to trust that the decisions are fair and based on sound reasoning. Without transparency, users might reject the system, fearing that the model is biased, incorrect, or arbitrary.
Example: Imagine a bank uses an AI model to assess creditworthiness. If the model rejects a loan application, the applicant needs to understand why. XAI could provide a clear explanation, such as, “Your credit score is below the required threshold,” or “You have a history of missed payments,” making the rejection less frustrating and more transparent.
- Improved Accountability and Fairness
Explainable AI is crucial for ensuring that machine learning models are fair and not making decisions based on biased data. If an AI model’s decisions cannot be explained, it becomes difficult to identify whether the model is making biased or discriminatory decisions.
Example: In recruitment, an AI system might recommend candidates based on resumes. Without XAI, it would be impossible to know if the model is biased against certain demographics. With explainability tools, the developers can track how the model weighs factors like gender, education, or experience to ensure fairness.
- Regulatory Compliance
As AI continues to play a larger role in sectors like healthcare, finance, and insurance, regulatory bodies are pushing for transparency in how AI models operate. Governments around the world are introducing laws that require AI systems to be explainable, especially when the decisions impact people’s rights or opportunities.
Example: The European Union’s General Data Protection Regulation (GDPR) includes a provision for the “right to explanation,” which means that individuals can ask companies to explain decisions made by automated systems.
- Debugging and Model Improvement
XAI not only helps users understand how models work but also allows developers to understand and improve the model’s behavior. When the model is not performing as expected, XAI can help reveal why the model is making certain decisions, leading to better troubleshooting and optimization.
Example: If a model is classifying images incorrectly, XAI can provide insights into which features (e.g., color, texture, shape) are being weighted too heavily, guiding developers on how to improve the model.
III. How Does Explainable AI Work?
- Model-Agnostic Methods
These methods work with any machine learning model, regardless of its underlying architecture. They help generate explanations by approximating the behavior of a complex model with a simpler, more interpretable one. Common techniques include:
- LIME (Local Interpretable Model-agnostic Explanations): LIME approximates a complex model with a simple model (like a linear regression) for a given prediction. It shows which features contributed most to the prediction, allowing users to understand the decision.
- SHAP (Shapley Additive Explanations): SHAP values break down predictions into contributions from each feature. It is based on cooperative game theory, where each feature is treated as a “player” in a game contributing to the final outcome.
- Model-Specific Methods
Some techniques work specifically with certain types of machine learning models, providing insights into how those models make decisions. For example:
- Decision Trees: Decision trees are naturally explainable because they represent decisions through a series of rules. The path taken from root to leaf shows the exact conditions that led to the decision.
- Feature Importance: In some models, like Random Forests, feature importance can be calculated to show which variables (features) are the most influential in making predictions.
- Visualization Tools
Visualization tools help translate the inner workings of a model into understandable graphics. For example, heatmaps or saliency maps in computer vision can show which parts of an image influenced the model’s decision the most.
Example: In a facial recognition system, XAI tools might highlight the areas of the face (eyes, nose, mouth) that the model is focusing on to make its prediction.
IV. Applications of Explainable AI in Backend Development
- Healthcare
In healthcare, the stakes are high, and decisions made by AI models can impact patient care. Using explainable AI, doctors and healthcare professionals can better understand the reasoning behind a model’s predictions, making it easier to trust and act on them.
Example: A model predicting the risk of a heart attack can explain that it made its decision based on a patient’s age, cholesterol levels, and family history of heart disease. This transparency can help doctors make better, more informed decisions.
- Finance
In the financial sector, AI models are often used to assess loan applications, detect fraud, or predict market trends. Explainable AI tools ensure that these decisions can be scrutinized and explained, providing better transparency for both customers and regulatory authorities.
Example: When an AI denies a loan application, XAI tools can clarify whether the decision was based on credit history, income level, or another factor, reducing confusion and improving customer trust.
- Autonomous Systems
Self-driving cars use AI models to make complex decisions in real time. However, it is essential that humans can understand how these decisions are made. Explainable AI helps autonomous vehicles explain their actions, such as why they decided to stop at an intersection or avoid a pedestrian.
V. Challenges of Explainable AI
While XAI has clear benefits, it is not without its challenges. Some of the difficulties include:
- Complexity vs. Explainability
Some machine learning models, particularly deep neural networks, are inherently complex. Trying to make them fully explainable can reduce their effectiveness. The more interpretable the model, the less complex it tends to be, which can result in decreased performance.
- Interpretability Trade-offs
There is often a trade-off between a model’s interpretability and its performance. Highly explainable models like decision trees are easy to understand but may not perform as well as more complex models like deep neural networks.
Pro Tip: When developing machine learning systems, always design with explainability in mind from the start. Implementing XAI techniques early on saves time and helps prevent costly redesigns later. It also fosters trust with users who need to understand how your model is making decisions.
Conclusion
Explainable AI is an essential component of modern machine learning, especially when building trust, ensuring fairness, and maintaining accountability in systems that impact people’s lives. By embracing XAI, developers can create more transparent, interpretable, and trustworthy AI models, paving the way for broader adoption of AI across industries. Whether in healthcare, finance, or autonomous vehicles, XAI helps ensure that the power of AI is used responsibly and that its decisions can be understood by humans.
Fun Fact: The term “Explainable AI” was first introduced to address concerns about AI’s “black box” nature in 2016, and it continues to evolve as AI systems grow more complex.
4. Real-World Applications and Success Stories
 Machine learning has become a game-changer in many industries, and its real-world applications are numerous and growing at an exponential rate. But how does machine learning (ML) work beyond the textbook and make a tangible impact on businesses, industries, and even individuals? This section will explore several exciting and impactful examples of machine learning in action, demonstrating how 15 innovative machine learning techniques are transforming backend development in diverse sectors.
Machine learning has become a game-changer in many industries, and its real-world applications are numerous and growing at an exponential rate. But how does machine learning (ML) work beyond the textbook and make a tangible impact on businesses, industries, and even individuals? This section will explore several exciting and impactful examples of machine learning in action, demonstrating how 15 innovative machine learning techniques are transforming backend development in diverse sectors.
I. Healthcare: Revolutionizing Patient Care and Diagnosis
Machine learning has made significant strides in healthcare, changing how diseases are diagnosed, treated, and monitored. With ML, backend systems can predict patient outcomes, identify diseases early, and even suggest personalized treatment plans based on vast datasets.
1. Disease Detection
Machine learning algorithms, particularly deep learning models, are being used to detect diseases in medical imaging. For example, ML is helping radiologists identify early-stage cancers in X-rays, MRIs, and CT scans. One successful implementation is Google’s DeepMind, which developed an AI system that can detect over 50 types of eye diseases with accuracy that rivals expert ophthalmologists. This system was trained using thousands of retinal scans and can help doctors diagnose eye conditions early, preventing blindness.
Fun Fact: Did you know that machine learning algorithms can sometimes outperform humans in diagnosing diseases? In fact, AI is showing promise in identifying conditions like breast cancer, skin cancer, and even Alzheimer’s disease years before they become evident to human doctors.
2. Predictive Analytics in Patient Monitoring
Machine learning models are also being used to predict patient outcomes and detect potential health risks. For instance, hospitals use predictive analytics to track patient vital signs and predict if a patient’s condition is likely to deteriorate. The Sepsis Prediction System in hospitals uses machine learning to analyze patient data and predict the onset of sepsis, a life-threatening condition, so that doctors can intervene before it becomes critical.
II. Finance: Enhancing Security and Improving Customer Experience
The financial industry has been one of the earliest adopters of machine learning, with banks and financial institutions using it to improve customer experience, reduce fraud, and enhance security.
1. Fraud Detection and Prevention
Banks and credit card companies rely on machine learning to detect and prevent fraud. By analyzing transaction data and customer behavior patterns, ML algorithms can identify abnormal activity in real-time. For example, PayPal uses ML models to flag potentially fraudulent transactions and automatically block them, protecting users and saving time for human security teams.
2. Personalized Financial Advice
In finance, recommendation systems powered by machine learning are also making waves. Robo-advisors use ML to analyze clients’ financial data and investment goals to recommend personalized investment strategies. Betterment, a popular robo-advisor, uses machine learning to help clients invest in a diversified portfolio based on their risk tolerance and financial objectives.
III. Retail: Improving Customer Experience with Personalization
Machine learning has also found a significant place in retail, where businesses are using it to enhance the customer shopping experience, boost sales, and manage inventory more efficiently.
1. Personalized Product Recommendations
Personalized recommendations are one of the biggest success stories of machine learning in retail. Amazon and Netflix are two prime examples of companies using recommendation systems to tailor their offerings to individual users. These recommendation engines analyze past browsing and purchasing behaviors and predict what other products customers might be interested in.
Pro Tip: If you’re building a recommendation system for your online business, make sure to focus on data that’s relevant to your customers. Tailor product recommendations based on factors like browsing history, purchase frequency, and seasonal trends.
2. Inventory Management with Predictive Analytics
Machine learning is also used to optimize inventory management. Walmart uses predictive analytics to forecast demand for various products, ensuring that the right amount of stock is available when needed. This helps avoid overstocking (which leads to higher storage costs) or understocking (which leads to lost sales). ML algorithms analyze factors like weather patterns, holidays, and historical sales data to make more accurate predictions.
IV. Autonomous Vehicles: Driving the Future of Transportation
Self-driving cars are one of the most exciting and high-profile applications of machine learning. These vehicles rely heavily on machine learning algorithms to navigate, make decisions, and react to real-time data from their environment.
1. Object Detection and Collision Avoidance
Autonomous vehicles use deep learning models to process data from sensors like cameras and LIDAR (Light Detection and Ranging). These sensors feed real-time information into the vehicle’s backend system, allowing the car to detect objects, recognize traffic signs, and predict the behavior of other drivers. For example, Tesla’s Autopilot uses machine learning to identify pedestrians, cyclists, and other vehicles, enabling the car to avoid collisions while driving on highways.
2. Predictive Maintenance for Vehicles
Machine learning is also used to predict when a vehicle might require maintenance, helping to prevent breakdowns and reduce repair costs. By analyzing historical data, including sensor readings and vehicle performance, machine learning models can predict when parts are likely to fail and suggest timely maintenance. This is a key aspect of General Motors’ OnStar system, which uses machine learning to track car performance and notify drivers about needed repairs before a breakdown occurs.
V. Entertainment: Enhancing Content Creation and User Experience
In the entertainment industry, machine learning is not just helping with content recommendation but also assisting in content creation, marketing, and audience engagement.
1. Content Recommendations
Streaming platforms like Spotify and YouTube use machine learning to recommend music and videos to users based on their preferences. These platforms use collaborative filtering and content-based filtering techniques to analyze user behavior, compare it with other users, and provide personalized recommendations that users are likely to enjoy.
2. Content Creation
Machine learning is also being used to create content. OpenAI’s GPT-3, for example, is capable of generating text based on a given prompt, which has applications in journalism, scriptwriting, and even poetry. This technique is starting to be adopted by content creators and marketers, who use AI-generated content to automate parts of their writing process.
VI. Marketing and Advertising: Targeting the Right Audience
Machine learning is transforming the way businesses engage with customers, providing them with the ability to deliver personalized advertisements and targeted marketing campaigns.
1. Ad Targeting and Personalization
Machine learning helps companies deliver targeted advertisements by analyzing user data and behavior. For example, Facebook and Google use ML algorithms to show ads to users based on their browsing history, interests, and demographics. This helps businesses improve ad relevance, increase conversions, and optimize their marketing strategies.
2. Sentiment Analysis for Brand Monitoring
Machine learning models also play a role in monitoring brand reputation by analyzing social media mentions, reviews, and customer feedback. Sentiment analysis uses natural language processing (NLP) techniques to determine whether online mentions are positive, negative, or neutral, allowing brands to adjust their marketing strategies accordingly.
Conclusion
Machine learning is transforming a wide range of industries, from healthcare to entertainment, finance to retail, and beyond. The real-world applications and success stories are numerous, and businesses are increasingly relying on innovative machine learning techniques to improve processes, enhance customer experiences, and drive growth. Whether it’s improving patient care with predictive analytics, preventing fraud in banking, or providing personalized product recommendations in retail, machine learning is truly revolutionizing the way we live and work.
Machine learning techniques are not just for big companies either. With the tools and technologies available today, even small businesses and startups can harness the power of machine learning to make smarter decisions, optimize backend operations, and deliver superior products and services.
Fun Fact: The first machine learning algorithm was created in 1959 by Arthur Samuel, who used it to teach a computer how to play checkers. Today, machine learning has come a long way from checkers — now we can use it to predict health outcomes, drive cars, and even recommend your next binge-worthy Netflix show!
5. Challenges and Considerations
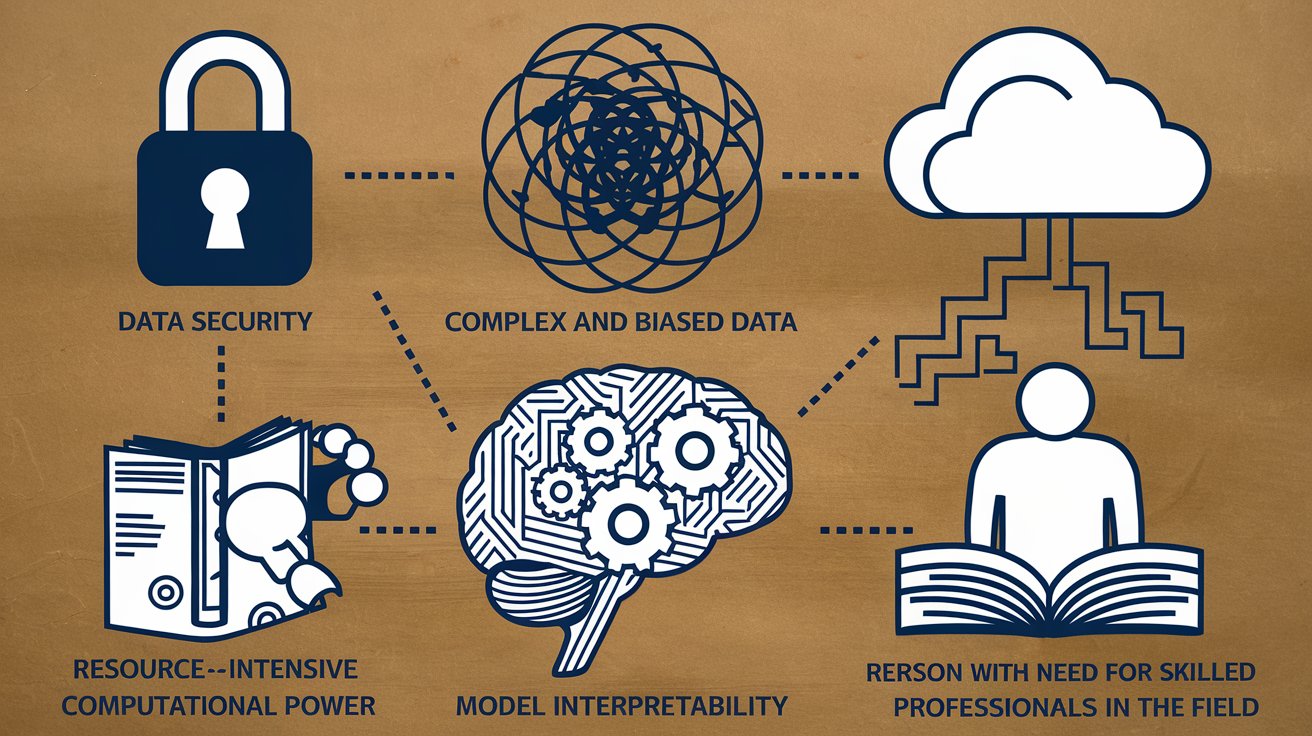 Machine learning is undoubtedly a game-changer in many industries, transforming everything from healthcare to entertainment. But as with all new technologies, there are challenges and considerations that must be addressed to make sure that machine learning is being used effectively, ethically, and safely. While ML techniques can drive massive innovation, organizations and developers must understand and navigate these hurdles to maximize the benefits.
Machine learning is undoubtedly a game-changer in many industries, transforming everything from healthcare to entertainment. But as with all new technologies, there are challenges and considerations that must be addressed to make sure that machine learning is being used effectively, ethically, and safely. While ML techniques can drive massive innovation, organizations and developers must understand and navigate these hurdles to maximize the benefits.
In this section, we’ll dive into the key challenges that come with implementing machine learning in backend development and discuss the considerations that must be kept in mind for successful adoption. So, buckle up – it’s time to look behind the curtain at some of the things you might not see at first glance when it comes to ML.
I. Data Privacy and Security: Protecting Sensitive Information
1. The Importance of Data Security
One of the most significant concerns when deploying machine learning is ensuring that sensitive data is kept secure. With large amounts of personal, financial, and medical data being processed, it’s crucial that machine learning models don’t expose confidential information. Whether you’re working with healthcare records or financial transactions, mishandling data can lead to privacy violations and security breaches.
2. Adherence to Regulations
In many industries, strict regulations govern how personal data should be handled. In the healthcare industry, for example, organizations must comply with regulations such as HIPAA (Health Insurance Portability and Accountability Act), which ensures the confidentiality and security of patient data. Similarly, in the EU, the GDPR (General Data Protection Regulation) sets clear guidelines on data protection, influencing how companies use ML models that rely on personal data. For backend developers, this means ensuring their ML systems are designed to protect privacy and comply with the relevant data protection laws.
Pro Tip: Always anonymize personal data where possible, and make sure you’re storing it securely. Regular audits and penetration tests can also help to find any vulnerabilities before they become a major problem.
II. Data Quality and Availability: Garbage In, Garbage Out
1. Clean, High-Quality Data is Crucial
One of the most important (and challenging) aspects of machine learning is data. ML algorithms learn from historical data, and if that data is inaccurate, incomplete, or biased, the results will be too. It’s often said that “garbage in, garbage out,” meaning that the quality of your results depends on the quality of your input data. Without clean, relevant, and representative data, ML models can make predictions that are inaccurate or outright misleading.
2. The Problem of Data Scarcity
Many industries face challenges related to the availability of high-quality data. For example, healthcare data may be limited in certain regions, or specific data might be difficult to obtain due to privacy concerns. In these cases, it’s important to find creative solutions, such as using synthetic data or collaborating with other organizations to pool resources.
3. Data Bias
Another critical issue in data is bias. If the data used to train an ML model is biased in some way, the model will likely reinforce these biases, leading to unfair or discriminatory outcomes. For example, a hiring algorithm trained on biased historical data might favor certain demographics over others, perpetuating inequality. It’s important to regularly audit the data and make adjustments to ensure that models are fair and unbiased.
III. Model Interpretability: Making Complex Decisions Transparent
1. The “Black Box” Problem
One of the most talked-about challenges in machine learning is model interpretability. Many machine learning algorithms, especially deep learning models, are highly complex and operate as “black boxes.” This means that, while the model might make accurate predictions, it’s not always clear how it arrived at those conclusions. This lack of transparency can be problematic, especially in industries like healthcare or finance, where understanding the reasoning behind a decision is crucial.
2. The Need for Explainable AI (XAI)
Explainable AI (XAI) aims to make machine learning models more transparent and understandable to humans. The goal is to ensure that ML systems can explain their decisions in a way that is clear and understandable, so that developers, as well as end users, can trust and verify the results. Without XAI, machine learning systems might not be able to explain why a diagnosis was made, why a loan was denied, or why a product was recommended.
This is why XAI is becoming increasingly important for industries that require a higher degree of accountability, like healthcare or financial services. The ability to interpret ML results is not only a technical challenge but also a crucial ethical concern.
IV. Resource Intensive: High Computational Demands
1. Processing Power and Costs
Machine learning models, particularly deep learning models, often require vast amounts of computing power to train. Training large-scale models can take days or even weeks, depending on the complexity of the data and the model itself. Not only does this require powerful hardware, but it can also be costly. For small businesses or startups, these resource requirements can be a major hurdle.
2. Cloud-Based Solutions
To combat the high computational costs, many businesses turn to cloud-based solutions. Platforms like AWS, Google Cloud, and Microsoft Azure offer machine learning tools and infrastructure that allow businesses to scale their ML systems without having to invest in expensive hardware. However, even these cloud services can rack up significant costs, especially when dealing with large datasets and complex models.
3. Energy Consumption
Another consideration is the environmental impact of training machine learning models. The energy consumption of large-scale machine learning tasks can be quite substantial, contributing to the carbon footprint of AI applications. For companies concerned about sustainability, it’s important to weigh the environmental cost against the potential benefits of machine learning and consider using energy-efficient models or strategies.
V. Skills Shortage: The Need for Skilled Professionals
Machine learning is still a relatively new field, and there’s a growing demand for professionals who understand how to implement and optimize ML systems. Unfortunately, there’s a skills shortage in the market, with many companies struggling to find qualified data scientists, machine learning engineers, and other specialized professionals. This is a major challenge for organizations that want to adopt machine learning but lack the in-house expertise.
1. Upskilling and Education
Fortunately, the demand for machine learning professionals is encouraging educational institutions and online platforms to ramp up their training programs. From universities to online courses like Coursera and Udacity, there are now many ways to learn about machine learning, data science, and artificial intelligence. For organizations, investing in the upskilling of their teams can help bridge the talent gap.
VI. Ethical Concerns: Navigating the Morality of ML Decisions
1. Bias and Fairness in Machine Learning
As mentioned earlier, one of the biggest concerns with machine learning is ensuring that algorithms are not biased or discriminatory. Whether it’s hiring practices, credit scoring, or law enforcement, ML systems must be designed to be fair and inclusive. Companies need to prioritize ethical considerations and ensure that their models are not inadvertently reinforcing harmful stereotypes or biases.
2. Accountability and Liability
In situations where ML systems make critical decisions, such as in healthcare or autonomous driving, accountability becomes a huge issue. Who is responsible if a machine learning system makes a wrong decision? Is it the developer, the company, or the machine itself? Clear guidelines and regulations are needed to establish accountability and ensure that there are no unintended consequences of automated decisions.
Conclusion
While machine learning offers vast opportunities for innovation, it’s not without its challenges. From ensuring data privacy to addressing biases in algorithms and tackling resource-intensive demands, backend developers and organizations need to carefully consider these hurdles before fully embracing ML technologies. It’s not just about building powerful algorithms – it’s about ensuring that those algorithms are secure, fair, and transparent. By understanding these challenges, we can better prepare for a future where machine learning can truly make a positive impact.
Summary of Machine Learning in Backend Development
Machine learning (ML) is revolutionizing backend development, offering innovative ways to optimize processes, enhance user experiences, and ensure system security. By leveraging data-driven models, ML enables backend developers to automate repetitive tasks, predict resource demands, detect anomalies, and even personalize content.
In backend development, ML techniques such as predictive analytics, anomaly detection, and recommendation systems help improve system performance and make smarter decisions. For instance, predictive analytics can optimize resource management, while anomaly detection can identify issues in system logs, ensuring smooth operations.
Moreover, natural language processing (NLP) for automation, reinforcement learning for task scheduling, and federated learning for distributed data processing allow backend systems to function more efficiently and securely. Automated Machine Learning (AutoML) simplifies model deployment, while unsupervised and supervised learning techniques help in user behavior prediction and data clustering.
However, while ML offers numerous benefits, it also presents challenges, such as ensuring data privacy, model interpretability, and dealing with computational costs. Addressing these challenges requires skilled professionals, quality data, and ethical practices to ensure that ML can be used responsibly and effectively.
FAQs About Machine Learning in Backend Development
1. What is Machine Learning in Backend Development?
Machine learning in backend development involves using algorithms and statistical models to allow backend systems to learn from data, improve processes, predict outcomes, and automate tasks. It helps enhance performance, security, and user experiences in backend systems.
2. How does Predictive Analytics help in Backend Development?
Predictive analytics in backend development helps anticipate future trends and resource requirements by analyzing historical data. This enables efficient resource management, preventing downtime or system overloads and optimizing server usage.
3. What are the Benefits of Anomaly Detection in Backend Systems?
Anomaly detection helps identify irregular patterns or potential issues in system logs. It improves backend system reliability by automatically spotting faults, cyberattacks, or unexpected behaviors, which would be difficult to catch manually.
4. How do Recommendation Systems Work in API Design?
Recommendation systems in API design use ML algorithms to suggest content, products, or services based on user preferences and behaviors. This personalization enhances user experience and engagement by delivering tailored recommendations.
5. What Role Does Natural Language Processing (NLP) Play in Automation?
NLP helps automate processes by enabling machines to understand and process human language. In backend development, NLP can be used to handle customer queries, analyze feedback, or automatically categorize data based on text inputs, streamlining communication and operations.
6. How Does Reinforcement Learning Help with Task Scheduling?
Reinforcement learning enables backend systems to learn the best strategies for scheduling tasks based on trial and error. It optimizes resource allocation by dynamically adjusting schedules to ensure tasks are completed efficiently while minimizing delays or conflicts.
7. What is Federated Learning and How is it Used in Backend Development?
Federated learning is a decentralized approach to training ML models on data distributed across multiple devices without sharing the data itself. In backend systems, it allows models to learn from user data securely, enhancing privacy while improving model accuracy.
8. What are the Challenges of Using Machine Learning in Backend Development?
Challenges include ensuring data privacy and security, managing high computational costs, dealing with biased or poor-quality data, and making models interpretable and transparent. Addressing these issues requires careful planning and skilled expertise in ML.
9. How Does Automated Machine Learning (AutoML) Simplify Model Deployment?
AutoML automates the process of selecting, training, and deploying machine learning models, making it easier for developers without deep expertise in ML to deploy effective models. It reduces the time and effort needed for model optimization and deployment.
10. Why is Model Interpretability Important in Backend Development?
Model interpretability ensures that developers and end-users can understand how ML models make decisions. It is essential for sectors like finance and healthcare, where transparency and accountability are critical to ensure fair and ethical decision-making.
Recommended Resources
Explore these authoritative resources to enhance your understanding of how machine learning can transform backend development:







